Video Discovery¶
In this step-by-step walkthrough, you'll build a conversational application that allows users to browse and find movies and TV shows from a large content catalog, using the MindMeld blueprint for this purpose.
Note
Please make sure to install and run all of the pre-requisites for MindMeld before continuing on with this blueprint tutorial.
1. The Use Case¶
Through a conversational interface, users should be able to browse a content catalog of movies and TV shows, then play what they find through a service similar to Netflix, Hulu, or Amazon Video.
2. Example Dialogue Interactions¶
The conversational flows for video discovery can be highly complex, depending on the desired app functionality and the amount of user guidance required at each step. Enumerating and finalizing all anticipated user interactions requires multiple iterations.
Here are some examples of scripted dialogue interactions for conversational flows.
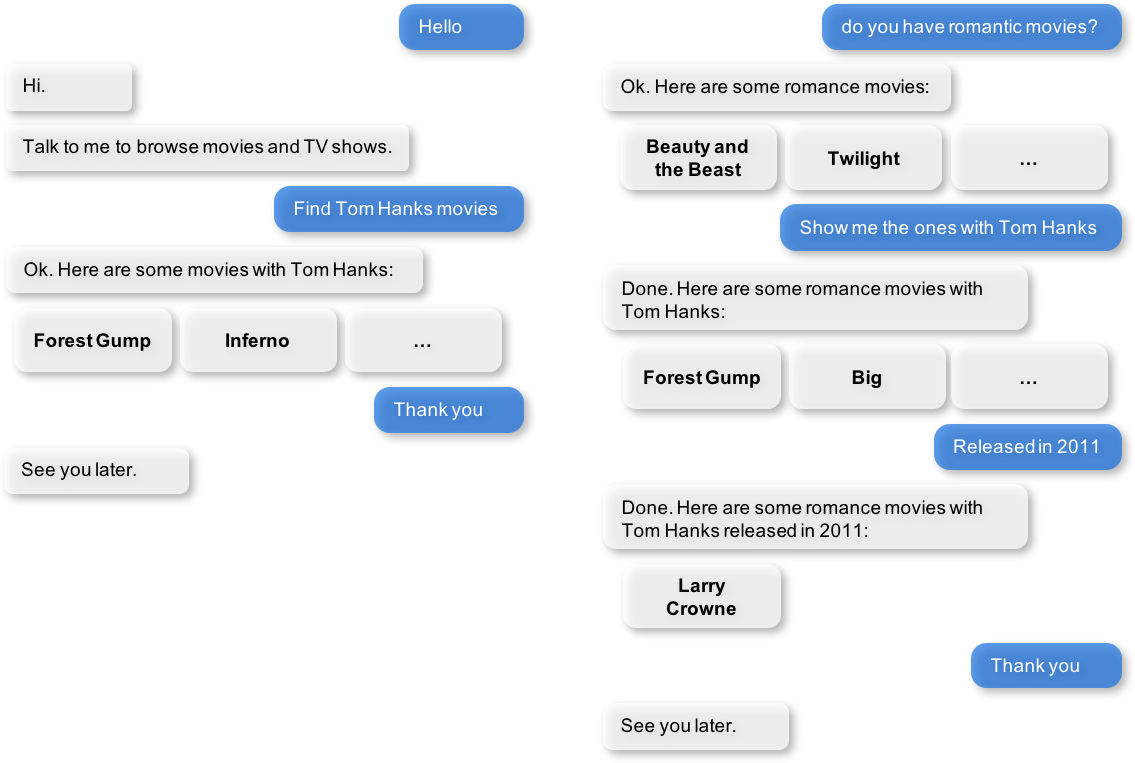
Exercise
Pick a convenient textual or graphical representation. Try to design as many user flows as you can. Always capture the entire dialogue from start to finish. Think of scenarios that differ from the examples above, such as: asking for something unrelated to movies and TV shows, asking for something with too many filters so there are no results, asking for something that is not in the app's catalog, and so on.
3. Domain-Intent-Entity Hierarchy¶
Users should be able to search for video content using common filters such as: genre, cast, release_year, and so on. They should be able to continue refining their search until they find the right content, and to restart the search whenever they like. Generic actions like greeting the user, providing help, and responding to insults and compliments should also be supported.
Based on this desired functionality, the developers of the video discovery app created the NLP model hierarchy below.
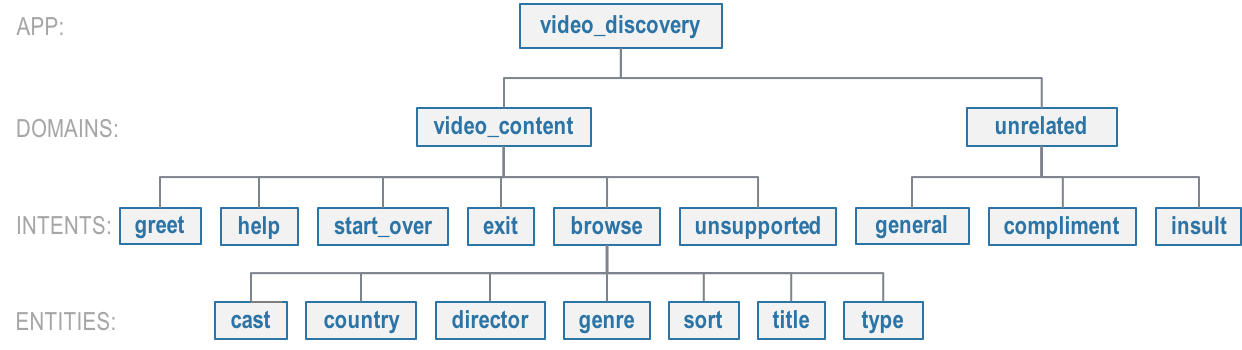
The are two domains:
video_content— Supports browsing the video catalogunrelated— Handles all requests not about video content
The video_content domain supports the following intents:
greet— User greets the apphelp— User is confused or needs instructions on how to proceedstart_over— User wants to abandon current selections and restart the ordering processexit— User wants to end the current conversationbrowse— User is searching for content, either for a specific movie or TV show, or for a set of resultsunsupported— User is asking for information related to movies or TV shows, but the app does not support those questions
- for example, asking when a movie was released, or when it will be shown on a given channel
The unrelated domain supports the intents:
general— User asks general questions unrelated to video content
- for example questions about weather, food, sports, etc.
compliment— User says something flattering to the appinsult— User says something hostile to the app
Only the browse intent requires entity recognition; it supports the following entity types:
cast— The name of an actorcountry— The name of the country of origin of a movie or TV showdirector— The name of a directorgenre— The name of a video genresort— How the users want to sort the results: by most recent, most popular, etc.title— The title of a video in the catalogtype— The type of video the user is looking for: movie or TV show
Exercise
While the blueprint provides a good starting point, you may need additional intents and entities to support the desired scope of your app. Enumerate some other intents (e.g., get_cast_in_video, get_release_year_for_video, and so on) and entities (e.g., writers, budget, and so on) that make sense for a video discovery use case.
To train the different machine learning models in the NLP pipeline for this app, we need labeled training data that covers all our intents and entities. To download the data and code required to run this blueprint, run the command below in a directory of your choice.
Warning
This application requires Elasticsearch for the QuestionAnswerer. Please make sure that Elasticsearch is running in another shell before proceeding to setup this blueprint.
python -c "import mindmeld as mm; mm.blueprint('video_discovery');"
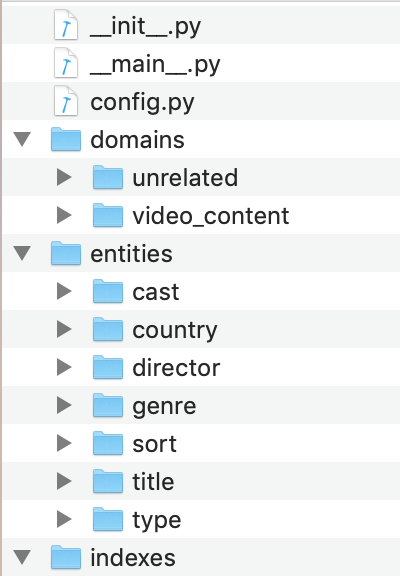
This should create a MindMeld project folder called video_discovery in your current directory with the following structure:
4. Dialogue States¶
To support the functionality we envision, our app needs one dialogue state for each intent, as shown in the table below.
Intent
|
Dialogue State
name
|
Dialogue State
function
|
|---|---|---|
greet |
welcome |
Begin an interaction and welcome the user
|
browse |
show_content |
Show the user a set of results and
refine them as the user provides more details
|
start_over |
start_over |
Cancel the ongoing search
and prompt the user for a new request
|
exit |
say_goodbye |
End the current interaction
|
help |
provide_help |
Provide help information
in case the user gets stuck
|
unsupported |
handle_unsupported |
Inform user the app does not provide that
information and get them back to video search
|
compliment |
say_something_nice |
Compliment the user back and prompt the user
to get back to video search
|
insult |
handle_insult |
Handle the insult and prompt the user
to get back to video search
|
other intents
|
default |
Prompt a user who has gone off-topic
to get back to video search
|
All dialogue states and their associated handlers are defined in the __init__.py application container file at the top level of the blueprint folder.
Handler logic can be simple, complex, or in between. At one end of this spectrum, the handler simply returns a canned response, sometimes choosing randomly from a set of responses. A more sophisticated handler could execute knowledge base queries to fill in the slots of a partially-templatized response. And a handler that applies more complex business logic could call an external API, process what the API returns, and incorporate the result into the response template.
The handler logic is fairly straightforward for most of our dialogue states. The main actions are choosing from a set of pre-scripted natural language responses, and replying to the user. These simple states include welcome, start_over, say_goodbye, provide_help, handle_unsupported, say_something_nice, handle_insult and default.
For example, here's the say_goodbye state handler, where we clear the dialogue frame and use the responder object to reply with one of our scripted "goodbye" responses:
@app.handle(intent='exit')
def say_goodbye(request, responder):
"""
When the user ends a conversation, clear the dialogue frame and say goodbye.
"""
responder.frame = {}
goodbyes = ['Bye!', 'Goodbye!', 'Have a nice day.', 'See you later.']
responder.reply(goodbyes)
By contrast, the handler logic for the show_content dialogue state is more substantial, because it contains the core business logic for our application. In this dialogue state handler, we use the Question Answerer to process the transaction.
You can see this in the general implementation of the show_content handler:
@app.handle(intent='browse')
def show_content(request, responder):
"""
When the user looks for a movie or TV show, fetch the documents from the knowledge base
with all entities we have so far.
"""
# Update the frame with the new entities extracted.
update_frame(request.entities, responder.frame)
# Fetch results from the knowledge base using all entities in frame as filters.
results = get_video_content(responder.frame)
# Fill the slots with the frame.
responder.slots.update(browse_slots_for_frame(request.frame))
# Build response based on available slots and results.
reply, video_payload = build_browse_response(responder, results)
responder.reply(reply)
# Build and return the directive
responder.list(video_payload)
This code follows a series of steps to build the final answer to the user: it updates the dialogue frame with the new found entities, fetches results from the knowledge base (in the get_video_content method), builds a response with the new entities (done in browse_slots_for_frame and build_browse_response), and sends a response to the user.
For more information on the show_content method and the functions it uses, see the __init__.py file in the blueprint folder.
5. Knowledge Base¶
The knowledge base for our video discovery app leverages publicly available information about movies and TV shows from the The Movie DB website. The knowledge base comprises one index in Elasticsearch:
videos— information about movies and TV shows
For example, here's the knowledge base entry in the videos index for "Minions," a comedy movie in 2015:
{
'genres': ['Family', 'Animation', 'Adventure', 'Comedy'],
'id': 'movie_211672',
'countries': ['US'],
'vote_count': 3660,
'runtime': 91,
'title': 'Minions',
'overview': 'Minions Stuart, Kevin and Bob are recruited by Scarlet Overkill, a super-villain who, alongside her inventor husband Herb, hatches a plot to take over the world.',
'doc_type': 'movie',
'release_date': '2015-06-17',
'img_url': 'http://image.tmdb.org/t/p/w185//q0R4crx2SehcEEQEkYObktdeFy.jpg',
'vote_average': 6.4,
'release_year': 2015,
'cast': ['Sandra Bullock', 'Jon Hamm', 'Michael Keaton', 'Allison Janney', 'Steve Coogan', 'Jennifer Saunders', 'Geoffrey Rush', 'Steve Carell', 'Pierre Coffin',
'Katy Mixon', 'Michael Beattie', 'Hiroyuki Sanada', 'Dave Rosenbaum', 'Alex Dowding', 'Paul Thornley', 'Kyle Balda', 'Ava Acres'],
'directors': ['Kyle Balda', 'Pierre Coffin'],
'imdb_id': 'tt2293640',
'popularity': 2.295467321653707
}
Another entry in the videos index is for "The Big Bang Theory," a comedy TV show from 2007:
{
'genres': ['Comedy'],
'id': 'tv-show_1418',
'countries': ['US'],
'vote_count': 1698,
'runtime': null,
'title': 'The Big Bang Theory',
'number_of_seasons': 10,
'overview': 'The Big Bang Theory is centered on five characters living in Pasadena, California: roommates Leonard Hofstadter and Sheldon Cooper; Penny, a waitress and aspiring actress who lives across the hall; and Leonard and Sheldon's equally geeky and socially awkward friends and co-workers, mechanical engineer Howard Wolowitz and astrophysicist Raj Koothrappali. The geekiness and intellect of the four guys is contrasted for comic effect with Penny's social skills and common sense.',
'doc_type': 'tv-show',
'release_date': '2007-09-24',
'img_url': 'http://image.tmdb.org/t/p/w185//wQoosZYg9FqPrmI4zeCLRdEbqAB.jpg',
'vote_average': 7,
'release_year': 2007,
'cast': ['Johnny Galecki', 'Jim Parsons', 'Kaley Cuoco', 'Simon Helberg', 'Kunal Nayyar', 'Mayim Bialik', 'Melissa Rauch'],
'directors': [],
'number_of_episodes': 231,
'popularity': 3.2740931003620037
}
Assuming that you have Elasticsearch installed, running the blueprint() command described above should build the knowledge base for the video discovery app by creating the one index and importing all the necessary data. To verify that the knowledge base has been set up correctly, use the Question Answerer to query the indexes.
Warning
Make sure that Elasticsearch is running in a separate shell before invoking the QuestionAnswerer.
from mindmeld.components.question_answerer import QuestionAnswerer
qa = QuestionAnswerer(app_path='video_discovery')
qa.get(index='videos', _sort='popularity', _sort_type='desc')[0]
{
'cast': ['Gal Gadot', 'Chris Pine', 'Connie Nielsen', ...],
'countries': ['US'],
'directors': ['Patty Jenkins'],
'doc_type': 'movie',
'genres': ['Action', 'Adventure', 'Fantasy', 'Science Fiction'],
'id': 'movie_297762',
'imdb_id': 'tt0451279',
'img_url': 'http://image.tmdb.org/t/p/w185//gfJGlDaHuWimErCr5Ql0I8x9QSy.jpg',
'overview': 'An Amazon princess comes to the world of Man to become the greatest of the female superheroes.',
'popularity': 4.904354681204688,
'release_date': '2017-05-30',
'release_year': 2017,
'runtime': 141,
'title': 'Wonder Woman',
'vote_average': 7.1,
'vote_count': 1979
}
Exercise
The blueprint comes with a pre-configured, pre-populated knowledge base to help you get up and running quickly. Read the User Guide section on Question Answerer to learn how to create knowledge base indexes from scratch. Then, try creating one or more knowledge base indexes for your own data.
6. Training Data¶
The labeled data for training our NLP pipeline was created using both in-house data generation and crowdsourcing techniques. See Step 6 of the Step-By-Step Guide for a full description of this highly important, multi-step process. Be aware that at minimum, the following data generation tasks are required:
Purpose
|
Question (for crowdsourced data generators)
or instruction (for annotators)
|
|---|---|
Exploratory data generation
for guiding the app design
|
"How would you talk to a conversational app
to search for movies and TV shows?"
|
Targeted query generation
for training the Intent Classifier
|
browse: "What would you say to the appto find movies and TV shows you want to watch?
|
Targeted query annotation
for training the Entity Recognizer
|
browse: "Annotate all occurrences of cast,country, director, genre, sort, title, and type
names in the given query."
|
Targeted synonym generation
for training the Entity Resolver
|
country: "What names would you use to referto this country?"
genre: "What are the different ways in whichyou would refer to this genre?"
sort: "What are the different ways in whichyou would speficy to sort movies or TV shows?"
type: "What are the different ways in whichyou would refer to this type?"
|
The domains directory contains the training data for domain and intent classification and entity recognition. The entities directory contains the data for entity resolution. Both directories are at root level in the blueprint folder.
Exercise
- Study the best practices around training data generation and annotation for conversational apps in Step 6 of the Step-By-Step Guide. Following those principles, create additional labeled data for all the intents in this blueprint. Read more about NLP model evaluation and error analysis in the User Guide. Then apply what you have learned in evaluating your app, using your newly-created labeled data as held-out validation data.
- Complete the following exercise if you are extending the blueprint to build your own video discovery app. For app-agnostic, generic intents like
greet,exit, andhelp, start by simply reusing the blueprint data to train NLP models for your video discovery app. Forshow_contentand any other app-specific intents, gather new training data tailored to the relevant entities (title, cast, genre, etc.). Apply the approach you learned in Step 6.
7. Training the NLP Classifiers¶
Train a baseline NLP system for the blueprint app. The build() method of the NaturalLanguageProcessor class, used as shown below, trains the NLP system using the annotated data.
from mindmeld import configure_logs; configure_logs()
from mindmeld.components.nlp import NaturalLanguageProcessor
nlp = NaturalLanguageProcessor(app_path='video_discovery')
nlp.build()
Fitting domain classifier
No domain model configuration set. Using default.
Loading queries from file unrelated/insult/train.txt
Loading queries from file unrelated/general/train.txt
Loading queries from file unrelated/compliment/train.txt
Loading queries from file video_content/greet/train.txt
Loading queries from file video_content/browse/train_00.txt
...
Selecting hyperparameters using k-fold cross-validation with 10 splits
Best accuracy: 96.89%, params: {'fit_intercept': True, 'C': 10}
Fitting intent classifier: domain='unrelated'
No intent model configuration set. Using default.
Selecting hyperparameters using k-fold cross-validation with 10 splits
Best accuracy: 79.29%, params: {'class_weight': {0: 0.9618644067796609, 1: 1.0089999999999999, 2: 1.0395604395604394}, 'fit_intercept': False, 'C': 1000000}
Fitting entity recognizer: domain='unrelated', intent='insult'
No entity model configuration set. Using default.
There are no labels in this label set, so we don't fit the model.
Fitting entity recognizer: domain='unrelated', intent='general'
No entity model configuration set. Using default.
There are no labels in this label set, so we don't fit the model.
Fitting entity recognizer: domain='unrelated', intent='compliment'
No entity model configuration set. Using default.
There are no labels in this label set, so we don't fit the model.
Fitting intent classifier: domain='video_content'
No intent model configuration set. Using default.
Selecting hyperparameters using k-fold cross-validation with 10 splits
Best accuracy: 96.50%, params: {'class_weight': {0: 0.58072419281491583, 1: 3.4295944233206592, 2: 0.98992735400949983, 3: 5.1416666666666666, 4: 2.904694092827004, 5: 0.67738804829588872}, 'fit_intercept': False, 'C': 1000000}
Fitting entity recognizer: domain='video_content', intent='greet'
No entity model configuration set. Using default.
There are no labels in this label set, so we don't fit the model.
Fitting entity recognizer: domain='video_content', intent='help'
No entity model configuration set. Using default.
There are no labels in this label set, so we don't fit the model.
Fitting entity recognizer: domain='video_content', intent='browse'
No entity model configuration set. Using default.
Selecting hyperparameters using k-fold cross-validation with 5 splits
Best accuracy: 97.43%, params: {'penalty': 'l2', 'C': 100000000}
...
Tip
During active development, it helps to increase the MindMeld logging level to better understand what's happening behind the scenes. All code snippets here assume that logging level has been set to verbose.
To see how the trained NLP pipeline performs on a test query, use the process() method.
nlp.process("Show me movies with Brad Pitt")
{
"intent": "browse",
"entities": [
{
"role": null,
"type": "type",
"span": {
"start": 8,
"end": 13
},
"text": "movies",
"value": [
{
"cname": "movie",
"top_synonym": "movies",
"score": 18.921387
},
{
"cname": "tv-show",
"top_synonym": "tv miniseries",
"score": 1.684855
}
]
},
{
"role": null,
"type": "cast",
"span": {
"start": 20,
"end": 28
},
"text": "Brad Pitt",
"value": []
}
],
"text": "Show me movies with Brad Pitt",
"domain": "video_content"
}
For the data distributed with this blueprint, the baseline performance is already high. However, when extending the blueprint with your own custom video discovery data, you may find that the default settings may not be optimal and you could get better accuracy by individually optimizing each of the NLP components.
Start by inspecting the baseline configurations that the different classifiers use. The User Guide lists and describes the available configuration options. As an example, the code below shows how to access the model and feature extraction settings for the Intent Classifier.
ic = nlp.domains['video_content'].intent_classifier
ic.config.model_settings['classifier_type']
'logreg'
ic.config.features
{
"edge-ngrams": {
"lengths": [
1,
2
]
},
"bag-of-words": {
"lengths": [
1,
2
]
},
"in-gaz": {},
"gaz-freq": {},
"freq": {
"bins": 5
},
"exact": {
"scaling": 10
}
}
You can experiment with different learning algorithms (model types), features, hyperparameters, and cross-validation settings by passing the appropriate parameters to the classifier's fit() method.
For example, you can change the feature extraction settings to use bag of trigrams in addition to the default bag of words:
ic.config.features['bag-of-words']['lengths'].append(3)
ic.fit()
Fitting intent classifier: domain='video_content'
Selecting hyperparameters using k-fold cross-validation with 5 splits
Best accuracy: 98.36%, params: {'C': 10, 'class_weight': {0: 0.5805006811989102, 1: 3.431368821292776, 2: 0.9903185247275775, 3: 5.1444117647058825, 4: 2.906170886075949, 5: 0.6776020174232005}, 'fit_intercept': False}
You can use similar options to inspect and experiment with the Entity Recognizer and the other NLP classifiers. Finding the optimal machine learning settings is a highly iterative process involving several rounds of model training (with varying configurations), testing, and error analysis. See the User Guide for more about training, tuning, and evaluating the various MindMeld classifiers.
Exercise
Experiment with different models, features, and hyperparameter selection settings to see how they affect classifier performance. Maintain a held-out validation set to evaluate your trained NLP models and analyze misclassified test instances. Then, use observations from the error analysis to inform your machine learning experimentation. See the User Guide for examples and discussion.
8. Parser Configuration¶
The relationships between entities in the video discovery queries are simple ones. For example, in the annotated query content with {Tom Hanks|cast}, the cast entity is self-sufficient, in that it is not described by any other entity.
If you extended the app to support queries with more complex entity relationships, it would be necessary to specify entity groups and configure the parser accordingly. For example, in the query show me a {Tom Hanks|cast} {movie|type} and a {Jim Parsons|cast} {TV show|type}, we would need to relate the cast entities to the type entities, because one kind of entity describes the other. Each pair of related entities would form an entity group. For more about entity groups and parser configurations, see the Language Parser chapter of the User Guide.
Since we do not have entity groups in the video discovery app, we do not need a parser configuration.
9. Using the Question Answerer¶
The Question Answerer component in MindMeld is mainly used within dialogue state handlers for retrieving information from the knowledge base. For example, in our welcome dialogue state handler, we use the Question Answerer to retrieve the top ten entries in our videos index and present them as suggestions to the user. For that, we sort the videos by popularity when using the Question Answerer:
qa = QuestionAnswerer(app_path='video_discovery')
results = qa.get(index='videos',_sort='popularity', _sort_type='desc')
In general the show_content handler retrieves documents from the knowledge base in different ways, depending on the entities found in the user's queries.
Look at the show_content implementation in __init__.py to better understand the different ways you can leverage the knowledge base and Question Answerer to provide intelligent responses to the user. See the User Guide for an explanation of the retrieval and ranking mechanisms that the Question Answerer offers.
Exercise
Think of other important data that would be useful to have in the knowledge base for a video discovery use case. Identify the ways that data could be leveraged to provide a more intelligent user experience.
10. Testing and Deployment¶
Once all the individual pieces (NLP, Question Answererer, Dialogue State Handlers) have been trained, configured, or implemented, use the Conversation class in MindMeld to perform an end-to-end test of your conversational app.
For instance:
from mindmeld.components.dialogue import Conversation
conv = Conversation(nlp=nlp, app_path='video_discovery')
res = conv.say("Show me movies with Tom Hanks")
print(res[1])
{
"popularity": 2.421098262038164,
"release_year": 1994,
"title": "Forrest Gump",
"type": "movie"
}
{
"popularity": 2.0508595659379023,
"release_year": 1995,
"title": "Toy Story",
"type": "movie"
}
{
"popularity": 1.9535944065231545,
"release_year": 2016,
"title": "Inferno",
"type": "movie"
}
{
"popularity": 1.7609147922705308,
"release_year": 2006,
"title": "Cars",
"type": "movie"
}
{
"popularity": 1.6671147585314865,
"release_year": 2010,
"title": "Toy Story 3",
"type": "movie"
}
{
"popularity": 1.6247940018503824,
"release_year": 1999,
"title": "Toy Story 2",
"type": "movie"
}
{
"popularity": 1.5488280905081466,
"release_year": 2016,
"title": "Sully",
"type": "movie"
}
{
"popularity": 1.511799504408644,
"release_year": 1998,
"title": "Saving Private Ryan",
"type": "movie"
}
{
"popularity": 1.5008401625832901,
"release_year": 2002,
"title": "Catch Me If You Can",
"type": "movie"
}
{
"popularity": 1.4618024954460482,
"release_year": 1999,
"title": "The Green Mile",
"type": "movie"
}
The say() method packages the input text in a user request object and passes it to the MindMeld Application Manager to simulate a user interacting with the application. The method then outputs the textual part of the response sent by the app's Dialogue Manager. In the above example, we requested movies from a particular actor, in a single query. The app responded, as expected, with an initial response acknowledging the filters used and a list of videos.
You can also try out multi-turn dialogues:
>>> conv = Conversation(nlp=nlp, app_path='video_discovery')
>>> conv.say('Hi there!')
['Hey.', 'Tell me what you would like to watch today.', "Unsupported response: {'videos': [{'release_year': 2017, 'type': 'movie', 'title': 'Wonder Woman'}, {'release_year': 2017, 'type': 'movie', 'title': 'Beauty and the Beast'}, {'release_year': 2017, 'type': 'movie', 'title': 'Transformers: The Last Knight'}, {'release_year': 2017, 'type': 'movie', 'title': 'Logan'}, {'release_year': 2017, 'type': 'movie', 'title': 'The Mummy'}, {'release_year': 2017, 'type': 'movie', 'title': 'Kong: Skull Island'}, {'release_year': 2005, 'type': 'tv-show', 'title': 'Doctor Who'}, {'release_year': 2011, 'type': 'tv-show', 'title': 'Game of Thrones'}, {'release_year': 2010, 'type': 'tv-show', 'title': 'The Walking Dead'}, {'release_year': 2017, 'type': 'movie', 'title': 'Pirates of the Caribbean: Dead Men Tell No Tales'}]}", "Suggestions: 'Most popular', 'Most recent', 'Movies', 'TV Shows', 'Action', 'Dramas', 'Sci-Fi'"]
>>> conv.say('Show me Tom Hanks movies')
['Done. Here are some movies starring Tom Hanks:', "Unsupported response: {'videos': [{'release_year': 1994, 'type': 'movie', 'title': 'Forrest Gump'}, {'release_year': 1995, 'type': 'movie', 'title': 'Toy Story'}, {'release_year': 2016, 'type': 'movie', 'title': 'Inferno'}, {'release_year': 2006, 'type': 'movie', 'title': 'Cars'}, {'release_year': 2010, 'type': 'movie', 'title': 'Toy Story 3'}, {'release_year': 1999, 'type': 'movie', 'title': 'Toy Story 2'}, {'release_year': 2016, 'type': 'movie', 'title': 'Sully'}, {'release_year': 1998, 'type': 'movie', 'title': 'Saving Private Ryan'}, {'release_year': 2002, 'type': 'movie', 'title': 'Catch Me If You Can'}, {'release_year': 1999, 'type': 'movie', 'title': 'The Green Mile'}]}"]
>>> conv.say('romantic')
['Done. Here are some romance movies with Tom Hanks:', "Unsupported response: {'videos': [{'release_year': 1994, 'type': 'movie', 'title': 'Forrest Gump'}, {'release_year': 1988, 'type': 'movie', 'title': 'Big'}, {'release_year': 2011, 'type': 'movie', 'title': 'Larry Crowne'}, {'release_year': 1990, 'type': 'movie', 'title': 'Joe Versus the Volcano'}, {'release_year': 1984, 'type': 'movie', 'title': 'Splash'}, {'release_year': 1993, 'type': 'movie', 'title': 'Sleepless in Seattle'}, {'release_year': 1986, 'type': 'movie', 'title': 'The Money Pit'}, {'release_year': 2019, 'type': 'movie', 'title': 'Toy Story 4'}, {'release_year': 1998, 'type': 'movie', 'title': "You've Got Mail"}, {'release_year': 1986, 'type': 'movie', 'title': 'Nothing in Common'}]}"
>>> conv.say('from 2011')
['Perfect. Here are some romance movies with Tom Hanks from 2011:', "Unsupported response: {'videos': [{'release_year': 2011, 'type': 'movie', 'title': 'Larry Crowne'}]}"]]
Exercise
Test the app multiple times with different conversational flows. Keep track of all cases where the response does not make good sense. Then, analyze those cases in detail. You should be able to attribute each error to a specific step in our end-to-end processing (e.g., incorrect intent classification, missed entity recognition, unideal natural language response, and so on). Categorizing your errors in this manner helps you understand the strength of each component in your conversational AI pipeline and informs you about the possible next steps for improving the performance of each individual module.
Refer to the User Guide for tips and best practices on testing your app before launch.