Platform Architecture¶
The MindMeld Conversational AI Platform provides a robust end-to-end pipeline for building and deploying intelligent data-driven conversational apps. The high-level architecture of the platform is illustrated below.
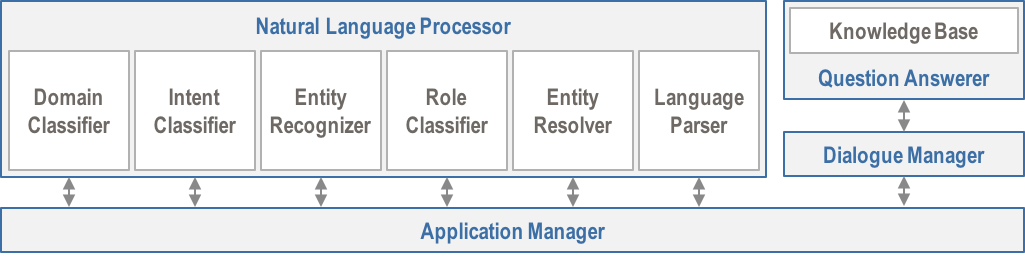
Note
The Application Manager, while part of MindMeld, orchestrates behind the scenes and never needs developer attention.
We will now explore the platform component by component.
Natural Language Processor¶
The Natural Language Processor (NLP) understands the user's query — that is, it produces a representation that captures all salient information in the query. This summarized representation is then used by the app to decide on a suitable action or response to satisfy the user's goals. (Throughout this guide the terms query and natural language input are interchangeable.)
The example below shows a user query and the resulting NLP output.
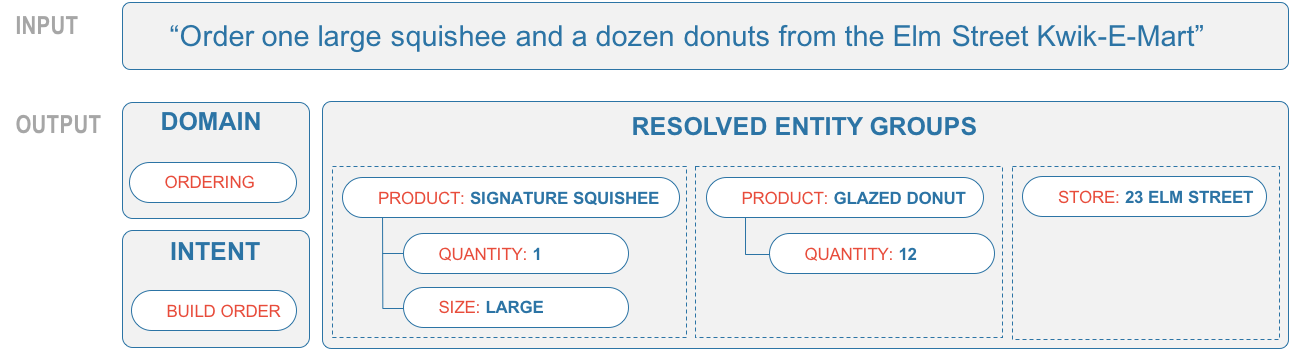
The Natural Language Processor analyzes the input using a hierarchy of machine-learned classification models, as introduced in Step 7. Apart from these classifiers, the NLP also has modules for entity resolution and language parsing. Altogether, this makes six subcomponents: a four-layer classification hierarchy, plus the entity resolution and language parsing modules.
The pipeline processes the user query sequentially in the left-to-right order shown in the architecture diagram above. In doing this, the NLP applies a combination of techniques such as pattern matching, text classification, information extraction, and parsing.
Next, we examine the role of each step in the NLP pipeline.
Domain Classifier¶
The Domain Classifier performs the first level of categorization on a user query by assigning it to one of a pre-defined set of domains that the app can handle. Each domain constitutes a unique area of knowledge with its own vocabulary and specialized terminology.
Consider a conversational app serving as a "Smart Home Assistant." This app would be expected to handle several distinct tasks, such as:
- Setting the temperature on a thermostat
- Toggling lights on and off in different rooms
- Locking and unlocking different doors
- Controlling multimedia devices around the home
- Answering informational queries about time, weather, etc.
The vocabularies for setting a thermostat and for interacting with a television are very different. These could therefore be modeled as separate domains — a thermostat domain and a multimedia domain (assuming that the TV is one of several media devices in the house). Personal assistants like Siri, Cortana, Google Assistant and Alexa are trained to handle more than a dozen different domains like weather, navigation, sports, music, calendar, etc.
On the opposite end of the spectrum are apps with just one domain. Usually, all the functions that such apps provide are conceptually related and span a single realm of knowledge. For instance, a "Food Ordering" app could potentially handle multiple tasks like searching for restaurants, getting more information about a particular restaurant, placing an order, etc. But the vocabulary used for accomplishing all of these tasks is almost entirely shared, and hence could be modeled as one single domain called food. The number of domains thus depends on the scope of the application.
To learn how to train a machine-learned domain classification model in MindMeld see the Domain Classifier section of this guide.
Intent Classifier¶
Once the NLP determines the domain to which a given query belongs, the Intent Classifier provides the next level of categorization by assigning the query to one of the intents defined for the app. Intents reflect what a user is trying to accomplish. For instance, the user may want to book a flight, search for movies from a catalog, ask about the weather, or set the temperature on a home thermostat. Each of these is an example of a user intent. The intent also defines the desired outcome for the query, by prescribing that the app take a specific action and/or respond with a particular type of answer.
Most domains in conversational apps have multiple intents. By convention, intent names are verbs that describe what the user is trying accomplish. Here are some example intents from the food domain in a "Food Ordering" app.
| Intent | Description |
|---|---|
| search_restaurant | Searching for restaurants matching a particular set of criteria |
| get_restaurant_info | Get information about a selected restaurant like hours, cuisine, price range, etc |
| browse_dish | List dishes available at a selected restaurant, filtered by given criteria |
| place_order | Place an order for pick up or delivery |
Every domain has its own separate intent classifier for categorizing the query into one of the intents defined within that domain. The app chooses the appropriate intent model at runtime, based on the predicted domain for the input query.
To learn how to train intent classification models in MindMeld, see the Intent Classifier section of this guide.
Entity Recognizer¶
The next step in the NLP pipeline, the Entity Recognizer, identifies every entity in the query that belongs to an entity type pre-defined as relevant to a given intent. An entity is any word or phrase that provides information necessary to understand and fulfill the user's end goal. For instance, if the intent is to search for movies, relevant entities would include movie titles, genres, and actor names. If the intent is to adjust a thermostat, the entity would be the numerical value for setting the thermostat to a desired temperature.
Most intents have multiple entities. By convention, entity names are nouns that describe the entity type. Here are some examples of entity types that might be required for different conversational intents.
| Domain | Intent | Entity Types |
|---|---|---|
| weather | check_weather | location, day |
| movies | find_movie | movie_title, genre, cast, director, release_date, rating |
| food | search_restaurant | restaurant_name, cuisine, dish_name, location, price_range, rating |
| food | browse_dish | dish_name, category, ingredient, spice_level, price_range |
Since the set of relevant entity types might differ for each intent (even within the same domain), every intent has its own entity recognizer. Once the app establishes the domain and intent for a given query, the app then uses the appropriate entity model to detect entities in the query that are specific to the predicted intent.
To learn how to build machine-learned entity recognition models in MindMeld, see the Entity Recognizer section of this guide.
Role Classifier¶
The Role Classifier is the last level in the four-layer NLP classification hierarchy. It assigns a differentiating label, called a role, to the entities extracted by the entity recognizer. Sub-categorizing entities in this manner is only necessary where an entity of a particular type can have multiple meanings depending on the context.
For example, "7 PM" and "midnight" could both be time entities. But in a query like "French restaurants open from 7 pm until midnight," one plays the role of an opening time while the other plays the role of a closing time. In this situation, the entity recognizer would categorize both as time entities, then the role classifier would label each entity with the appropriate role. Role classifiers are trained separately for each entity that requires the additional categorization.
Here are examples of some entity types that might require role classification when dealing with certain intents.
| Domain | Intent | Entity Type | Role Types |
|---|---|---|---|
| meeting | schedule_meeting | time | start_time, end_time |
| travel | book_flight | location | origin, destination |
| retail | search_product | price | min_price, max_price |
| banking | transfer_funds | account_num | sender, recipient |
To learn how to build role classification models in MindMeld, see the Role Classifier section of this guide.
Entity Resolver¶
The Entity Resolver was introduced in Steps 6 and 7 of the Step-By-Step Guide. Entity resolution entails mapping each identified entity to a canonical value that can be looked up in an official catalog or database. For instance, the extracted entity "lemon bread" could resolve to "Iced Lemon Pound Cake (Product ID: 470)" and "SF" could resolve to "San Francisco, CA."
Robust entity resolution is key to a seamless conversational experience because users generally refer to entities informally, using abbreviations, nicknames, and other aliases, rather than by official standardized names. The Entity Resolver in MindMeld ensures high resolution accuracy by applying text relevance algorithms similar to those used in state-of-the-art information retrieval systems. Each entity has its own resolver trained to capture all plausible names for the entity, and variants on those names.
To learn how to build entity resolvers in MindMeld, see the Entity Resolver section of this guide.
Language Parser¶
As described in the Step-By-Step Guide, the Language Parser is the final module in the NLP pipeline. The parser finds relationships between the extracted entities and clusters them into meaningful entity groups. Each entity group has an inherent hierarchy, representing a real-world organizational structure.
The parser arranges the resolved entities in the example above into three entity groups, where each group describes a distinct real-world concept:
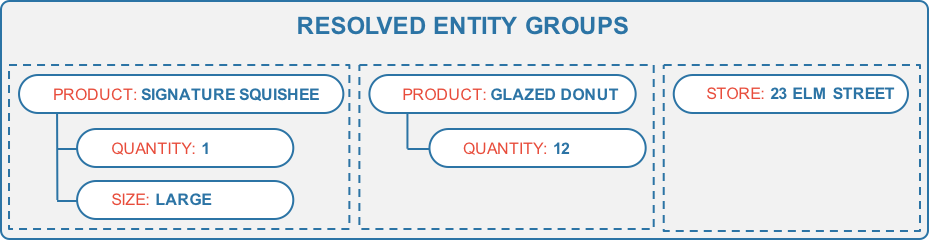
The first two groups represent products to be ordered, whereas the last group contains store information. We call the main entity at the top in each group the parent or the head whose children or dependents are the other entities in the group. The app can interpret this structured representation of the user's natural language input to decide on the next action and/or response. In the example, the next action might be to submit the order to a point-of-sale system, thus completing the user's order.
Most natural language parsers used in NLP academic research need to be trained using expensive treebank data, which is hard to find and annotate for custom conversational domains. The Language Parser in MindMeld, by contrast, is a configuration-driven rule-based parser which works out-of-the-box with no need for training.
To learn how to configure the MindMeld parser for optimum performance in a specific app, see the Language Parser section of this guide.
Now we have seen how the Natural Language Processor understands what the user wants. That is half of the job at hand. Responsibility for the other half — to respond appropriately to the user and advance the conversation — falls to the Question Answerer and the Dialogue Manager, respectively.
Question Answerer¶
Most conversational apps today rely on a Knowledge Base to understand user requests and answer questions. The knowledge base is a comprehensive repository of all the world knowledge that is important for a given application use case. The component responsible for interfacing with the knowledge base is called the Question Answerer. See Steps 5 and 9 of the Step-By-Step Guide.
The question answerer retrieves information from the knowledge base to identify the best answer candidates that satisfy a given set of constraints. For example, the question answerer for a restaurant app might rely on a knowledge base containing a detailed menu of all the available items, in order to identify dishes the user requests and to answer questions about them. Similarly, the question answerer for a voice-activated multimedia device might have a knowledge base containing detailed information about every song or album in a music library.
The MindMeld Question Answerer provides a flexible mechanism for retrieving and ranking relevant results from the knowledge base, with convenient interfaces for both simple and highly advanced searches.
For documentation and examples, see the Question Answerer section of this guide.
Dialogue Manager¶
The Dialogue Manager directs the flow of the conversation. It is a stateful component which analyzes each incoming query, then assigns the query to a dialogue state handler which in turn executes appropriate logic and returns a response to the user.
Architecting the dialogue manager correctly is often one of the most challenging software engineering tasks when building a conversational app for a non-trivial use case. MindMeld abstracts away many underlying complexities of dialogue management to offer a simple but powerful mechanism for defining application logic. MindMeld provides advanced capabilities for dialogue state tracking, beginning with a flexible syntax for defining rules and patterns for mapping requests to dialogue states. It also allows dialogue state handlers to invoke any arbitrary code for taking a specific action, completing a transaction, or obtaining the information necessary to formulate a response.
For a practical introduction to dialogue state tracking in MindMeld, see Step 4. The Dialogue Manager section of this guide provides further examples.
Application Manager¶
As the core orchestrator of the MindMeld platform, the Application Manager:
- Receives the client request from a supported endpoint
- Processes the request by passing it through all the MindMeld-trained components of the MindMeld platform
- Returns the final response to the endpoint once processing is complete
The application manager works behind the scenes, hidden from the MindMeld developer.
That concludes our quick tour of the MindMeld Conversational AI platform. The rest of this guide consists of hands-on tutorials focusing on using MindMeld to build data-driven conversational apps that run on the MindMeld platform.