Working with the Text Preparation Pipeline¶
The Text Preparation Pipeline
- is MindMeld's text processing module which handles the preprocessing, tokenization, normalization, and stemming of raw queries
- has extensible components that can be configured based on language-specific requirements
- offers components that integrate functionality from Spacy, NLTK and Regex
The TextPreparationPipeline processes text in the following order:
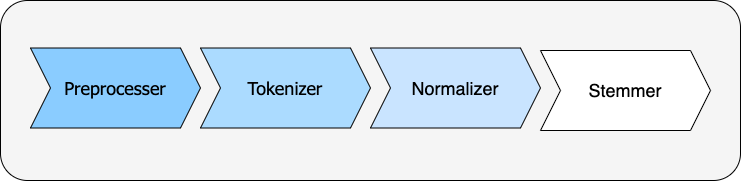
The diagram below is a visual example of a TextPreparationPipeline that uses Spacy for tokenization, Regex for normalization and NLTK for stemming.
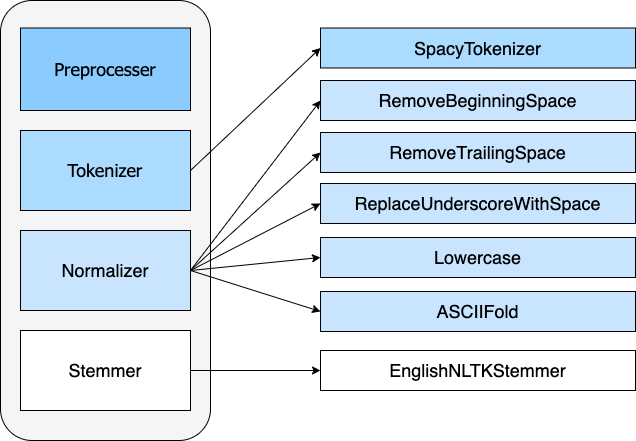
TextPreparationPipeline Configuration¶
The DEFAULT_TEXT_PREPARATION_CONFIG is shown below. Observe that various normalization classes
have been pre-selected by default. To modify the selected components (or to use a subset of the normalization steps), duplicate the
default config and rename it to TEXT_PREPARATION_CONFIG. Place this custom config in the config.py file for your application.
If a custom configuration is not defined, a default is used. The config below is an example of a default config specifically for English.
The normalizers component includes 12 default MindMeld regex normalization rules in addition to Lowercase and ASCIIFold.
DEFAULT_EN_TEXT_PREPARATION_CONFIG = {
"preprocessors": [],
"tokenizer": "WhiteSpaceTokenizer",
"normalizers": [
'RemoveAposAtEndOfPossesiveForm',
'RemoveAdjacentAposAndSpace',
'RemoveBeginningSpace',
'RemoveTrailingSpace',
'ReplaceSpacesWithSpace',
'ReplaceUnderscoreWithSpace',
'SeparateAposS',
'ReplacePunctuationAtWordStartWithSpace',
'ReplacePunctuationAtWordEndWithSpace',
'ReplaceSpecialCharsBetweenLettersAndDigitsWithSpace',
'ReplaceSpecialCharsBetweenDigitsAndLettersWithSpace',
'ReplaceSpecialCharsBetweenLettersWithSpace',
'Lowercase',
'ASCIIFold'
],
"regex_norm_rules": [],
"stemmer": "EnglishNLTKStemmer",
"keep_special_chars": r"\@\[\]'"
}
In general, the Tokenizer is the WhiteSpaceTokenizer by default and the Stemmer is dynamically selected based
on the language of the application, if they are not explicitly defined in the config. The table below explains these defaults:
| Config Element | Default | Condition |
|---|---|---|
| Preprocessors | None | Always |
| Normalizers | 12 Default MindMeld Regex Rules Lowercase ASCII Fold |
Always |
| Regex Norm Rules | None | Always |
| Tokenizer | WhiteSpaceTokenizer | Default for all languages. |
| Stemmer | EnglishNLTKStemmer | If the language is English. |
| SnowballStemmer | If the language is supported by NLTK's SnowballStemmer: Danish (da), Dutch (nl), Finnish (fi), French (fr), German (de), Hungarian (hu), Italian (it), Norwegian (nb), Portuguese (pt), Romanian (ro), Russian (ru), Spanish (es) and Swedish (sv). | |
| NoOpStemmer | If the language is not English and is not supported by NLTK's SnowballStemmer. | |
| keep_special_chars | @, [, ], ' | Always |
Let's define the parameters in the TextPreparationPipeline config:
'preprocessors' (List[str]): The preprocessor class to use. (Mindmeld does not currently offer default preprocessors.)
'tokenizer' (str): The tokenization method to split raw queries.
'normalizers' (List[str]): List of normalization classes. The text will be normalized sequentially given the order of the normalizers specified.
'keep_special_chars' (str): String containing characters to be skipped when normalizing/filtering special characters. This only applies for a subset of default MindMeld normalization rules.
'regex_norm_rules' (List[Dict]): Regex normalization rules represented as dictionaries. Each rule should have the key "pattern" and "replacement" which map to a
regex pattern (str) and replacement string, respectively. For example: { "pattern": "_", "replacement": " " }.
'stemmer (str): The stemmer class to reduce words to their word stem.
Note
If regex_norm_rules are specified in the config they will be applied before other normalization rules. This includes the default normalization rules if normalization rules are not explicitly defined in the config.
Preprocessing¶
By preprocessing text, we can make modifications to raw text before it is processed through the TextPreparationPipeline. Examples of some common preprocessing tasks include spelling correction, punctuation removal, handling special characters,
and other kinds of application-specific text normalization. Currently, MindMeld does not offer pre-built processors, however, the pipeline does support custom preprocessors.
Creating a Custom Preprocessor¶
This section includes boilerplate code to build a custom preprocessor class. Let's build a simple ASRPreprocessor class that corrects mistranscriptions which is a common problem with
Automatic Speech Recognition systems. A custom preprocessor must extend from MindMeld's abstract Preprocessor class:
from abc import ABC, abstractmethod
class Preprocessor(ABC):
"""
Base class for Preprocessor object
"""
@abstractmethod
def process(self, text):
"""
Args:
text (str)
Returns:
(str)
"""
pass
Now that we have a better understanding of the base class. Let's create a simple ASRPreprocessor class which implements the abstract preprocess method and replaces any substring of "croissant ready"
with the intended name, "prasanth reddy".
from mindmeld.text_preparation.preprocessors import Preprocessor
class ASRPreprocessor(Preprocessor):
""" Sample Preprocessor Class """
def process(self, text):
return text.replace("croissant ready", "Prasanth Reddy")
This would transform the transcript "Let's start the meeting with croissant ready." to "Let's start the meeting with Prasanth Reddy." The steps to use a custom Preprocessor in your application are explained here.
Tokenization¶
Tokenization is the process of splitting the text of a query into smaller chunks. MindMeld offers a number of ready-made tokenizers that you can use for your application. MindMeld supports the development of custom tokenizers as well.
White Space Tokenizer¶
The WhiteSpaceTokenizer splits up a sentence by whitespace characters. For example, we can run:
from mindmeld.text_preparation.tokenizers import WhiteSpaceTokenizer
sentence = "MindMeld is a Conversational AI Platform."
white_space_tokenizer = WhiteSpaceTokenizer()
tokens = white_space_tokenizer.tokenize(sentence)
print([t['text'] for t in tokens])
We find that the resulting tokens are split by whitespace as expected.
['MindMeld', 'is', 'a', 'Conversational', 'AI', 'Platform.']
Character Tokenizer¶
The CharacterTokenizer splits up a sentence by the individual characters. This can be helpful for languages such as Japanese. Let's break apart the Japanese translation for the phrase "The tall man":
from mindmeld.text_preparation.tokenizers import CharacterTokenizer
sentence_ja = "背の高い男性"
character_tokenizer = CharacterTokenizer()
tokens = character_tokenizer.tokenize(sentence_ja)
print([t['text'] for t in tokens])
We see that the original text is split at the character level.
['背', 'の', '高', 'い', '男', '性']
Letter Tokenizer¶
The LetterTokenizer splits text into a separate token if the character proceeds a space, is a
non-latin character, or is a different unicode category than the previous character.
This can be helpful to keep characters of the same type together. Let's look at an example with numbers in a Japanese sentence, "1年は365日". This sentence translates to "One year has 365 days".
from mindmeld.text_preparation.tokenizers import LetterTokenizer
sentence_ja = "1年は365日"
letter_tokenizer = LetterTokenizer()
tokens = letter_tokenizer.tokenize(sentence_ja)
print([t['text'] for t in tokens])
We see that the original text is split at the character level for non-latin characters but the number "365" remains as an unsegmented token.
['1', '年', 'は', '365', '日']
Spacy Tokenizer¶
The SpacyTokenizer splits up a sentence using Spacy's language models.
Supported languages include English (en), Spanish (es), French (fr), German (de), Danish (da), Greek (el), Portuguese (pt), Lithuanian (lt), Norwegian Bokmal (nb), Romanian (ro), Polish (pl), Italian (it), Japanese (ja), Chinese (zh), Dutch (nl).
If the required Spacy model is not already present it will automatically downloaded during runtime.
Let's use the SpacyTokenizer to tokenize the Japanese translation of "The gentleman is gone, no one knows why it happened!":
from mindmeld.text_preparation.tokenizers import SpacyTokenizer
sentence_ja = "背の高い男性"
spacy_tokenizer_ja = SpacyTokenizer(language="ja", spacy_model_size="sm")
tokens = spacy_tokenizer_ja.tokenize(sentence_ja)
We see that the original text is split semantically and not simply by whitespace.
['背', 'の', '高い', '男性']
Creating a Custom Tokenizer¶
This section includes boilerplate code to build a custom tokenizer class. Let's rebuild a CharacterTokenizer class that creates a token for each character in a string as long as the
character is not a space. A custom tokenizer must extend from MindMeld's abstract Tokenizer class:
from abc import ABC, abstractmethod
class Tokenizer(ABC):
"""Abstract Tokenizer Base Class."""
@abstractmethod
def tokenize(self, text):
"""
Args:
text (str): The text to tokenize.
Returns:
tokens (List[Dict]): List of tokenized tokens which a represented as dictionaries.
Keys include "start" (token starting index), and "text" (token text).
For example: [{"start": 0, "text":"hello"}]
"""
raise NotImplementedError("Subclasses must implement this method")
Note that any MindMeld tokenizer must return the final tokens as a list of dictionaries. Where each dictionary represents a single token and contains the "start" index of the token and the "text" of the token.
Here is an example of the expected output for the tokens generated when tokenizing the phrase "Hi Andy": [{"start": 0, "text":"Hi"}, {"start": 3, "text":"Andy"}]. The starting indices here refer to the starting indices in the processed text.
With this in mind, let's recreate MindMeld's CharacterTokenizer class which converts every individual character in a string into a separate token while skipping spaces.
from mindmeld.text_preparation.tokenizers import Tokenizer
class CharacterTokenizer(Tokenizer):
"""A Tokenizer that splits text at the character level."""
def tokenize(self, text):
tokens = []
for idx, char in enumerate(text):
if not char.isspace():
tokens.append({"start": idx, "text": char})
return tokens
This tokenizes the phrase "Hi Andy" in the following manner:
[
{'start': 0, 'text': 'H'},
{'start': 1, 'text': 'i'},
{'start': 3, 'text': 'A'},
{'start': 4, 'text': 'n'},
{'start': 5, 'text': 'd'},
{'start': 6, 'text': 'y'}
]
The steps to use a custom Tokenizer in your application are explained here.
Normalization¶
Normalization is the process of transforming text into a standardized form. MindMeld supports the use of multiple normalizers to be applied to the original raw query in a sequential manner.
MindMeld offers a number of pre-built normalizers that can be specified in the config.py file. MindMeld also supports the development of custom normalizers to meet
application-specific requirements.
Note
Normalization and Tokenization are conducted around MindMeld's entity annotations. For example, let's look at the query, "Where is {Andy Neff|person_name} located?".
Let's assume our normalization method is to use the Uppercase value of each character. The TextPreparationPipeline will normalize the query to become the following:
"WHERE IS {ANDY NEFF|person_name} LOCATED?". Notice that the entity name in the entity annotation is not modified. A similar process happens during tokenization. Another way to
think of this, is that the entity annotations are "temporarily removed" before normalization and then added back in.
Default Regex Normalization¶
By default, MindMeld uses 12 Regex-based normalization rules when normalizing texts (in addition to Lowercase and ASCIIFold). Descriptions for these 12 rules can be found in the table below.
| Regex Normalization Rule | Description | Example Input | Example Output |
|---|---|---|---|
| RemoveAposAtEndOfPossesiveForm | Removes any apostrophe following an 's' at the end of a word. | "dennis' truck" | "dennis truck" |
| RemoveAdjacentAposAndSpace | Removes apostrophes followed by a space character and apostrphes that precede a space character. | "havana' " | "havana" |
| RemoveBeginningSpace | Removes extra spaces at the start of a word. | " MindMeld" | "MindMeld" |
| RemoveTrailingSpace | Removes extra spaces at the end of a word. | "MindMeld " | "MindMeld" |
| ReplaceSpacesWithSpace | Replaces multiple consecutive spaces with a single space. | "How are you?" | "How are you?" |
| ReplaceUnderscoreWithSpace | Replaces underscore with a single space. | "How_are_you?" | "How are you?" |
| SeparateAposS | Adds a space before 's. | "mindmeld's code" | "mindmeld 's code" |
| ReplacePunctuationAtWordStartWithSpace | Replaces special characters infront of words with a space. | "HI %#++=-=SPERO" | "HI SPERO" |
| ReplacePunctuationAtWordEndWithSpace | Replaces special characters following words with a space. | "How%+=* are++- you^^%" | "How are you" |
| ReplaceSpecialCharsBetweenLettersAndDigitsWithSpace | Replaces special characters between letters and digits with a space. | "Coding^^!#%24 hours#%7 days" | "Coding 24 hours 7 days" |
| ReplaceSpecialCharsBetweenDigitsAndLettersWithSpace | Replaces special characters between digits and letters with a space. | "Coding 24^^!#%%hours 7##%days" | "Coding 24 hours 7 days" |
| ReplaceSpecialCharsBetweenLettersWithSpace | Replaces special characters between letters and letters with a space. | "Coding all^^!#%%hours seven##%days" | "Coding all hours seven days" |
The last 5 rules (ReplacePunctuationAtWordStartWithSpace, ReplacePunctuationAtWordEndWithSpace, ReplaceSpecialCharsBetweenLettersAndDigitsWithSpace, ReplaceSpecialCharsBetweenDigitsAndLettersWithSpace, ReplaceSpecialCharsBetweenLettersWithSpace) above remove special characters in different contexts. These special characters can be specified in the config using the key, keep_special_chars.
By default, keep_special_chars includes @, [, ] and ' represented as a single string. A custom set of special characters can be specified in config.py.
Lowercase Normalization¶
The Lowercase normalizer converts every character in a string to its lowercase equivalent. For example:
from mindmeld.text_preparation.normalizers import Lowercase
sentence = "I Like to Run!"
lowercase_normalizer = Lowercase()
normalized_text = lowercase_normalizer.normalize(sentence)
print(normalized_text)
As expected, this would display the following normalized text:
'i like to run!'
ASCII Fold Normalization¶
The ASCIIFold normalizer converts numeric, symbolic and alphabetic characters which are not in the first 127 ASCII characters (Basic Latin Unicode block) into an ASCII equivalent (if possible).
For example, we can normalize the following Spanish sentence with several accented characters:
from mindmeld.text_preparation.normalizers import ASCIIFold
sentence_es = "Ha pasado un caballero, ¡quién sabe por qué pasó!"
ascii_fold_normalizer = ASCIIFold()
normalized_text = ascii_fold_normalizer.normalize(sentence_es)
print(normalized_text)
The accents are removed and the accented characters have been replaced with compatible ASCII equivalents.
'Ha pasado un caballero, ¡quien sabe por que paso!'
Unicode Character Normalization¶
Unicode Character Normalization includes techniques such as NFD, NFC, NFKD, NFKC.
These methods break down characters into their canonical or compatible character equivalents as defined by unicode.
Let's take a look at an example. Say we are trying to normalize the word quién using NFKD.
from mindmeld.text_preparation.normalizers import NFKD
nfd_normalizer = NFKD()
text = "quién"
normalized_text = nfd_normalizer.normalize(text)
Interestingly, we find that the normalized text looks identical with the original text, it is not quite the same.
>>> print(text, normalized_text)
>>> quién quién
>>> print(text == normalized_text)
>>> False
We can print the character values for each of the texts and observe the the normalization has actually changed the representaation for é.
>>> print([ord(c) for c in text])
>>> [113, 117, 105, 233, 110]
>>> print([ord(c) for c in normalized_text])
>>> [113, 117, 105, 101, 769, 110]
Creating a Custom Normalizer¶
This section includes boilerplate code to build a custom normalizer class. Let's recreate the Lowercase normalizer class.
A custom tokenizer must extend from MindMeld's abstract Normalizer class:
from abc import ABC, abstractmethod
class Normalizer(ABC):
"""Abstract Normalizer Base Class."""
@abstractmethod
def normalize(self, text):
"""
Args:
text (str): Text to normalize.
Returns:
normalized_text (str): Normalized Text.
"""
raise NotImplementedError("Subclasses must implement this method")
With this in mind, let's recreate MindMeld's Lowercase normalizer class.
from mindmeld.text_preparation.normalizers import Normalizer
class Lowercase(Normalizer):
def normalize(self, text):
return text.lower()
This normalizer would transform the text "I Like to Run!" to "i like to run!". The steps to use a custom Normalizer in your application are explained here.
Note
MindMeld normalizes queries on a per-token basis. Custom normalizers should be designed to normalize individual tokens and not sentences as a whole.
Stemming¶
Stemming is the process of reducing a word to its stem or root. If a stemmer is not specified in the TEXT_PREPARATION_CONFIG, then MindMeld will automatically select a stemmer
based on the language of the application.
EnglishNLTKStemmer¶
The EnglishNLTKStemmer stemmer uses a modified version of the PorterStemmer from the nltk library.
The Porter stemmer implements a series of rules that removes common suffixes, and this version of it removes inflectional suffixes but leaves (most) derivational suffixes in place.
This includes removing the final letters "s"/"es" from plural words or "ing" from gerunds, but leaving more meaningful suffixes like "tion" and "ment" alone.
Let's take a look at a few examples of the EnglishNLTKStemmer. First we'll make an instance of the stemmer:
from mindmeld.text_preparation.stemmers import EnglishNLTKStemmer
english_nltk_stemmer = EnglishNLTKStemmer()
Now let's stem the words "running" and "governments".
>>> print(english_nltk_stemmer.stem_word("running"))
>>> run
>>> print(english_nltk_stemmer.stem_word("governments"))
>>> government
As expected, the stemmer removes "ing" from "running" and the "s" from "governments" to create stemmed words.
SnowballNLTKStemmer¶
The SnowballNLTKStemmer stemmer works in a similar manner to the EnglishNLTKStemmer, however, it removes more suffixes and offers support for a larger set of languages.
Namely, the SnowballNLTKStemmer supports Danish (da), Dutch (nl), Finnish (fi), French (fr), German (de), Hungarian (hu), Italian (it), Norwegian (nb), Portuguese (pt), Romanian (ro), Russian (ru), Spanish (es) and Swedish (sv).
To create an instance of the SnowballNLTKStemmer, we can use MindMeld's StemmerFactory.
from mindmeld.text_preparation.stemmers import SnowballNLTKStemmer
es_snowball_stemmer = SnowballNLTKStemmer("spanish")
Now let's stem the words "corriendo" ("running") and "gobiernos" ("governments").
>>> print(es_snowball_stemmer.stem_word("corriendo"))
>>> corr
>>> print(es_snowball_stemmer.stem_word("gobiernos"))
>>> gobi
As expected, the stemmer removes "iendo" from "corriendo" and the "ernos" from "gobiernos" to create stemmed words.
Creating a Custom Stemmer¶
This section includes boilerplate code to build a custom stemmer class.
A custom stemmer must extend from MindMeld's abstract Stemmer class:
from abc import ABC, abstractmethod
class Stemmer(ABC):
@abstractmethod
def stem_word(self, word):
"""
Gets the stem of a word. For example, the stem of the word 'fishing' is 'fish'.
Args:
word (str): The word to stem
Returns:
stemmed_word (str): A stemmed version of the word
"""
raise NotImplementedError
Let's create a stemmer that uses Spacy's lemmatization functionality to use lemmatized tokens. We'll call it the SpacyLemmatizer.
from mindmeld.text_preparation.stemmers import Stemmer
class SpacyLemmatizer(Stemmer):
def __init__(self):
self.nlp = spacy.load('en_core_web_sm')
def stem_word(self, word):
"""
Args:
word (str): The word to stem
Returns:
stemmed_word (str): A lemmatized version of the word
"""
doc = self.nlp(word)
return " ".join([token.lemma_ for token in doc])
The SpacyLemmatizer would transform "ran" to "run".
The steps to use a custom Stemmer in your application are explained in the section below.
Using a Custom TextPreparationPipeline for your Application¶
As a recap, every MindMeld project is also a Python package and has an __init.py__ file at the root level.
This package also contains an application container -- a container for all of the logic and functionality for your application.
This application container enumerates all of the dialogue states and their associated handlers, and should be defined as app in the application's Python package.
To use a TextPreparationPipeline with custom components, we must pass in a custom object into the application container in __init.py__.
Let's first take a look at an example of an __init.py__ file before a custom TextPreparationPipeline used.
from mindmeld import Application
app = Application(__name__)
@app.handle(intent='greet')
def welcome(request, responder):
responder.reply('Hello')
Now let's look at this __init.py__ file after a custom TextPreparationPipeline is used.
To isolate the logic and functionality of our custom TextPreparationPipeline let's create the object in a separate file at the root level, we'll call it text_preparation_pipeline.py.
text_preparation_pipeline.py will contain a function get_text_preparation_pipeline() which we can use to pass the custom pipeline into the application container.
from mindmeld import Application
from .text_preparation_pipeline import get_text_preparation_pipeline
app = Application(__name__, text_preparation_pipeline=get_text_preparation_pipeline())
@app.handle(intent='greet')
def welcome(request, responder):
responder.reply('Hello')
In the text_preparation_pipeline.py file we'll implement the get_text_preparation_pipeline() method which returns a custom TextPreparationPipeline object.
Let's piece together multiple custom components into a single TextPreparationPipeline. We will define and use an ASRPreprocessor, GerundSuffixStemmer and RemoveExclamation normalizer.
In the code below, we have created each of our components by implementing the respective MindMeld abstract classes.
In get_text_preparation_pipeline() we first create a default TextPreparationPipeline using the TextPreparationPipelineFactory. This factory class uses the specifications in the config for the application which is
identified by the current path. A series of setter methods are used to update components. Finally, the modified pipeline is returned.
from mindmeld.text_preparation.text_preparation_pipeline import TextPreparationPipelineFactory
from mindmeld.text_preparation.preprocessors import Preprocessor
from mindmeld.text_preparation.stemmers import Stemmer
from mindmeld.text_preparation.normalizers import Normalizer
class ASRPreprocessor(Preprocessor):
def process(self, text):
return text.replace("croissant ready", "Prasanth Reddy")
class GerundSuffixStemmer(Stemmer):
def stem_word(self, word):
if word.endswith("ing"):
return word[:-len("ing")]
return word
class RemoveExclamation(Normalizer):
def normalize(self, text):
return text.lower()
def get_text_preparation_pipeline():
text_preparation_pipeline = TextPreparationPipelineFactory.create_from_app_config("./")
text_preparation_pipeline.set_preprocessors([ASRPreprocessor()])
text_preparation_pipeline.normalizers.append(RemoveExclamation())
text_preparation_pipeline.set_stemmer(GerundSuffixStemmer())
return text_preparation_pipeline