Step-by-Step Guide to Active Learning with Log Data in MindMeld¶
Active learning is an approach to continuously and iteratively pick data that is most informative for the models to train on from a pool of unlabeled data points. By picking such data-points, active learning provides a higher chance of improving the accuracy of the model with fewer training examples. It also greatly reduces the number of queries to be annotated by humans. MindMeld provides this inbuilt functionality to select these must-have queries from existing data or additional logs and datasets to get the best out of your conversational applications.
The following step-by-step guide will use the HR Assistant blueprint for showcasing MindMeld's active learning functionality and the different customizations involved.
Step 1: Setup a MindMeld App with Log Resources¶
The first step for running active learning is to set up your MindMeld app with log data configured for the app. This log data can either be in the form of labeled text files (similar to the train and test files in the app), or an unlabeled text file containing raw text queries across all domains and intents.
For the purpose of this tutorial, we will generate 'logs' for the current HR Assistant blueprint using the MindMeld Data Augmentation pipeline. These paraphrases will serve as additional queries for the app to train on. After we have figured out the best hyperparameters using the tuning step, we'll select the best queries from the data augmentation logs (files with the pattern train-augmented.txt). Adding these queries to the train files of the assistant can improve the performance of the classifiers.
Note
Install the additional dependencies for active learning:
pip install mindmeld[active_learning]
or in a zsh shell:
pip install mindmeld"[active_learning]"
Step 2: Define Active Learning Config¶
This section shows the customized active learning configuration setting in config.py for the HR Assistant app. A detailed description for each of the components can be found here.
ACTIVE_LEARNING_CONFIG = {
"output_folder": "hr_assistant_active_learning",
"pre_tuning": {
"train_pattern": ".*train.txt",
"test_pattern": ".*test.*.txt",
"train_seed_pct": 0.05,
},
"tuning": {
"n_classifiers": 3,
"n_epochs": 1,
"batch_size": 100,
"tuning_level": "domain",
"tuning_strategies": [
"LeastConfidenceSampling",
"MarginSampling",
"EntropySampling",
"RandomSampling",
"DisagreementSampling",
"EnsembleSampling",
"KLDivergenceSampling",
],
},
"tuning_output": {
"save_sampled_queries": True,
"aggregate_statistic": "accuracy",
"class_level_statistic": "f_beta",
},
"query_selection": {
"selection_strategy": "EntropySampling",
"log_usage_pct": 1.00,
"labeled_logs_pattern": train-augmented.txt,
"unlabeled_logs_path": None,
},
}
The "output_folder" refers to a directory that will house all saved results from the active learning tuning and selection steps.
In the sections below, we will breakdown the different components of this config into their respective steps.
Step 3: Run Strategy Tuning and Evaluate Hyperparameters¶
Before we jump into tuning, let us discuss the pre_tuning configurations. This section covers the data patterns that the active learning pipeline ingests. The train_pattern is a regex field to provide the set of files across domains and intents that can be chosen as training files for the classifier. The test_pattern similarly represents the test files for the classifier that are used for iterative model evaluation and performance comparisons. The train_seed_pct is the percentage of training data that is used as the seed for training the initial model. This data is evenly sampled across domains and the rest is unsampled, to be used in the tuning process.
For the strategy tuning step, the following command is run:
mindmeld active_learning --tune --app-path "hr_assistant" --output_folder "hr_assistant_active_learning"
This runs the tuning process for all the sampling strategies specified under the tuning_strategies subconfig in the tuning configuration. It repeats the process for n_epochs and generates results and plots in a folder within the output directory.
The results include two files for every tuning run, one to store the evaluation results across iterations and epochs against the test data and another file indicating the queries that were selected at each iteration. These evaluation and query selection results can be found in the directory hr_assistant_active_learning/<experiment_folder>/results in files accuracies.json and selected_queries.json respectively. Plots for the tuning results are saved in hr_assistant_active_learning/<experiment_folder>/plots. The experiment directory is unique to every tuning command run.
Next, one of two tuning levels needs to be set for the pipeline. For this experiment, we show results across the domain tuning level. For changing to intent level active learning, the tuning_level can be set to 'intent' in the config while keeping the rest of the experiment the same. The next couple of blocks show how results for a single iteration of the Least Confidence Sampling heuristic are stored in the accuracies.json and selected_queries.json respectively.
# accuracies.json
{
"LeastConfidenceSampling": {
"0": {
"0": {
"num_sampled": 455,
"accuracies": {
"overall": 0.8872727272727273
}
}
}
}
}
# selected_queries.json
{
"LeastConfidenceSampling": {
"0": {
"0": [
{
"unannotated_text": "Amy date of fire",
"annotated_text": "{Amy|name} {date of fire|employment_action}",
"domain": "date",
"intent": "get_date"
},
{
"unannotated_text": "question needs answering",
"annotated_text": "question needs answering",
"domain": "faq",
"intent": "generic"
},
{
"unannotated_text": "what is ivan's job title",
"annotated_text": "what is {ivan|name}'s {job title|position}",
"domain": "general",
"intent": "get_info"
}
]
}
}
}
The selected queries are stored both with the entity annotations and just as raw text, along with the domain and intent classification labels.
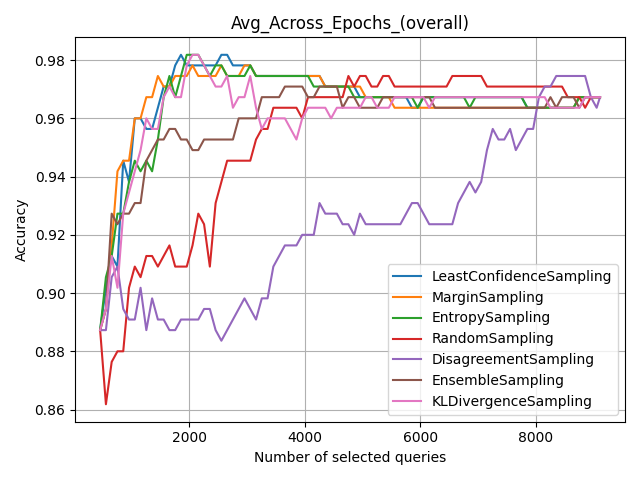
The plots directory houses two types of plots to give a better visual understanding of the tuning results. The first is a line graph indicating the performance of the various sampling/tuning strategies over iterations, with each iteration covering the newly sampled data in that iteration. The following graph shows that entropy sampling is one of the best performing sampling strategies in the earlier iterations. Another way to interpret this is that entropy sampling learns the distribution of the data better with fewer samples as compared to other strategies. This makes it useful for query selection from logs.
The second graph type is a stacked bar chart for every sampling strategy, indicating the distribution of the selected queries across domains per iteration of data selection. The following plot is the stacked bar chart for entropy sampling.
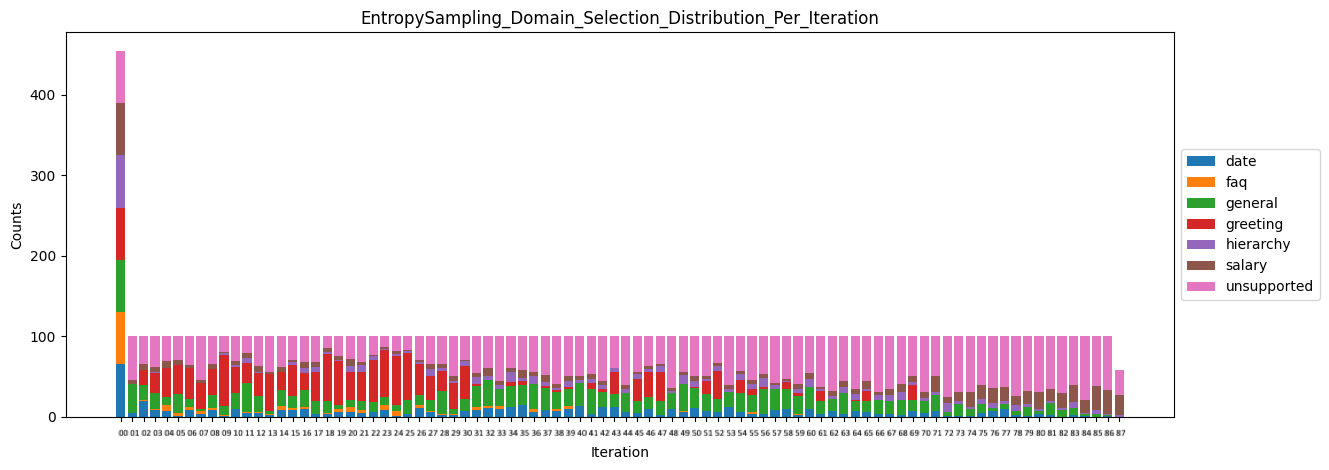
Looking at these results, one can decide on the best strategy for the query selection phase. We choose entropy sampling as the best strategy hyperparameter for this experiment with the HR Assistant application.
Step 4: Select Best Queries¶
Once the hyperparameters are set, the query selection step of the active learning pipeline is used to select the best queries from user logs. To generate synthetic logs for the HR assistant blueprint application, we use MindMeld's data augmentation capabilities. First, we add the following config:
AUGMENTATION_CONFIG = {
"augmentor_class": "EnglishParaphraser",
"batch_size": 8,
"paths": [
{
"domains": ".*",
"intents": ".*",
"files": "train.txt",
}
],
"path_suffix": "-augmented.txt"
}
Next, we run the augmentation step:
mindmeld augment --app_path "hr_assistant"
This process results in train-augmented.txt files being generated for each of the train.txt files in the application's intents.
Now for selection, the configuration for the active learning query selection step should have the new augmented files as the labeled_log_pattern and the chosen selection strategy:
"query_selection": {
"selection_strategy": "EntropySampling",
"log_usage_pct": 1.00,
"labeled_logs_pattern": train-augmented.txt,
"unlabeled_logs_path": None,
},
Once fixed, query selection is run as follows:
mindmeld active_learning --select --app-path "hr_assistant" --output_folder "hr_assistant_active_learning"
This results in the generation of selected_queries.json file in the output directory. It consists of queries that have been selected by the active learning pipeline and that were further annotated by the bootstrap annotator. An example is shown next:
{
"strategy": "EntropySampling",
"selected_queries": [
{
"unannotated_text": "i need money for all of the employees who have us citizenship.",
"annotated_text": "i need money for all of the employees who have us citizenship.",
"domain": "salary",
"intent": "get_salary_employees"
},
{
"unannotated_text": "get me the name donna brill.",
"annotated_text": "get me the name {donna brill|name}.",
"domain": "general",
"intent": "get_info"
},
{
"unannotated_text": "please get me the dob of julissa hunts.",
"annotated_text": "please get me the {dob|dob} of {julissa hunts|name}.",
"domain": "date",
"intent": "get_date"
}
]
}
If instead the logs were raw text and not annotated for domain and intent, then they could be collated into a single text file and passed into the configuration instead of the logs pattern as follows:
"query_selection": {
"selection_strategy": "EntropySampling",
"log_usage_pct": 1.00,
"labeled_logs_pattern": None,
"unlabeled_logs_path": "logs.txt",
},
or using the flag --unlabeled_logs_path at runtime for the select command. The result would be a similar selected_queries.json file in the output directory.
The selected queries can then be added back to the training data and can improve the performance of the NLP classifiers.