Step 6: Generate Representative Training Data¶
Supervised machine learning is the technology behind today's most successful and widely used conversational applications, and data sets are the fuel that power all supervised learning algorithms. Even for simple applications, the combinatorial complexity of human language makes rule-based approaches intractable. Supervised machine learning, on the other hand, has proven remarkably effective at understanding human language by observing large amounts of representative training data. Most MindMeld components rely on supervised machine learning algorithms that learn from thousands or millions of training examples.
A supervised learning model is only as smart as its underlying training data. Therefore, generating comprehensive and representative training data is critical to ensure the success of any application. High-quality data, also called labeled data, is not only the substrate upon which your models are built — it is also the yardstick used to measure performance. By standard practice, a portion of your labeled data always serves as the 'ground truth' used to score the accuracy of your underlying model. When you judge one model against another, the model whose output is closer to the 'ground truth' is the better model. As you might imagine, this 'ground truth' can only be a meaningful metric if derived from labeled data which accurately depicts desired application performance.
Many different strategies exist for generating training data. Which approach is best depends on the stage of development your application is in and the scope of your particular use case. For new applications that are not yet receiving any production traffic, training data sets are typically generated using manual data entry or crowdsourcing. In some cases, data sets can be derived by mining the web. For live applications with production traffic, data sets can sometimes be generated either from customer traffic logs or by instrumenting the application to collect user interaction signals. In all cases, multiple layers of quality assurance are typically required to ensure that the training data is high-quality, error-free, and representative of desired application performance.
Five of the core supervised learning components in MindMeld rely on training data. Depending on the use case, a given application may need data for some or all of these components:
- Domain Classification
- Intent Classification
- Entity Recognition
- Role Classification
- Entity Resolution
As described in Step 3, the structure of your application's root directory in MindMeld organizes the training data files. For our example Kwik-E-Mart store information application, the application directory is shown below.
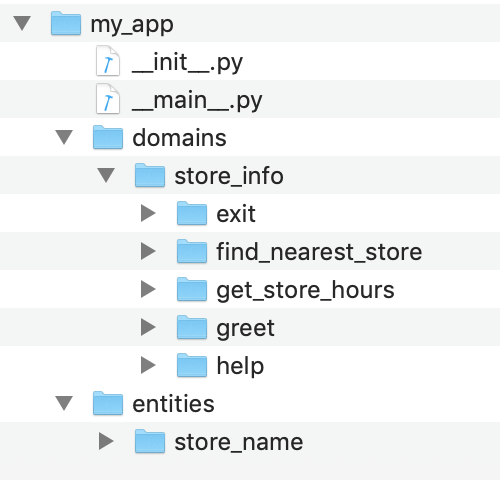
While training data is always stored in text files, there are two different types of data files used for training in MindMeld. These types of training data files, and their mandatory locations, are described in the table below.
| Labeled Queries | Labeled query files are text files containing example user queries. MindMeld uses them to train the domain and intent classification models. Labeled query files also support an inline markup syntax for annotating entities and entity roles within each query. These annotations are used to train both the entity and role classification models. All labeled query files belong in the domains folder. Each domain and intent subfolder should contain labeled query files that apply only to that intent. The hierarchical structure of the domains folder provides the classification labels used to train the domain and intent classification models. |
| Entity Mappings | Entity mappings are JSON files which associate whitelisted alternate names, or synonyms, with individual entities. MindMeld uses entity mappings to train the models required for entity resolution. These files belong in the entities folder. |
We will now illustrate the typical structure for these two types of training data files.
Labeled Query Files¶
Labeled query files are the primary source of training data for the MindMeld natural language processing classifiers. They are text files containing annotated example queries, one per line. Each file should contain queries which apply to a single intent only. All the labeled query files for a given intent must be placed in the folder for that intent, which is a subfolder of the domains folder. For our example Kwik-E-Mart application, the domains directory could be organized as follows.
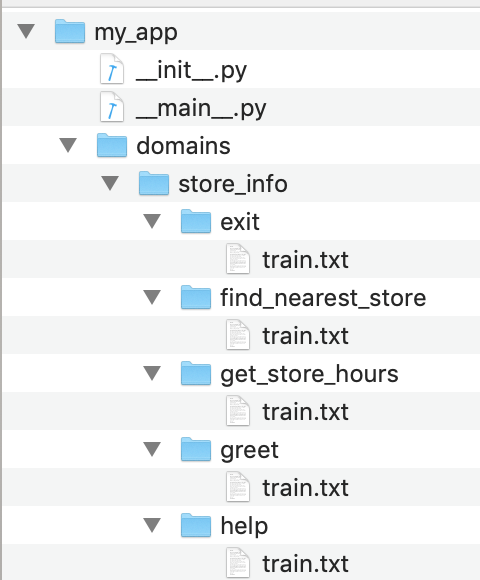
Since this application contains only a single domain, store_info, a domain classifier is not necessary. If additional domains were present, we would need separate sets of training queries for each domain. By default, training data for a given domain consists of the union of all labeled queries for all intents belonging to that domain. For example, training queries for the store_info domain would consist of the union of all queries in the greet, get_store_hours, find_nearest_store, exit and help intents.
Since the store_info domain contains multiple intents, we will use the labeled query text files to train the intent classifier for this domain. The example queries in each individual file should illustrate the typical language patterns associated with each intent.
For example, the train.txt file under the greet intent folder captures many of the different ways you might expect your users to express a greeting:
Hello
Good morning!
How are you?
greetings
How's it going?
What's up?
...
The train.txt file in the exit intent folder captures many of the different ways a user might exit your application:
bye
Good bye!
See you later.
quit
sayonara
...
The train.txt file for the get_store_hours intent captures ways that a user might ask about store hours. In this file, we see the annotation scheme for inline entities, because the get_store_hours intent supports the two entity types: store_name and sys_time, as you might recall from Step 3.
When does the {Elm Street|store_name} store close?
What are the hours for the Kwik-E-Mart on {Main Street|store_name}?
Is the {Central Plaza|name} Kwik-E-Mart open now?
The store at {Pine & Market|store_name} - is it open?
Is the {Rockefeller|store_name} Kwik-E-Mart open for business {tomorrow|sys_time}?
Can you check if the {Main St|store_name} store is open on {Sunday|sys_time}?
...
As the example shows, each inline entity is appended by the pipe character followed by its associated entity type, then the entire expression is enclosed in curly braces. Annotations for names of system entities, which are built into MindMeld, begin with sys_. In the example, time is a system entity. This simple annotation scheme provides a convenient way to label entities in order to derive the training data required to train the entity recognizer models.
Labeled queries can also be used to train role classification models. This is not a requirement for our Kwik-E-Mart application, but to illustrate how it might work, consider the following user query:
- "Show me all Kwik-E-Mart stores open between 8am and 6pm."
Here, both 8am and 6pm could be defined as entities, perhaps of type sys_time. While the two entities share the same type, they play different roles in the query; one reflects the store opening time and the other is the store closing time. MindMeld provides the capability to train models to perform this role classification. Simply supplement your labeled queries with additional role annotation, as shown below.
Show me all Kwik-E-Mart stores open between {8am|sys_time|open_time} and {6pm|sys_time|close_time}.
Are there any Kwik-E-Mart stores open after {3pm|sys_time|open_time}?
...
Entity Mapping Files¶
Entity mapping files specify the training data required for entity resolution. Entity resolution is the task of mapping each entity to a unique and unambiguous concept, such as a product with a specific ID or an attribute with a specific SKU number. In some cases, this mapping may be obvious. For example, the phrase 'Eiffel Tower' may always unambiguously refer to famous Paris landmark. In most applications, though, users describe the same object in many varied ways. For example, some people might refer to 'Bruce Springsteen' as 'The Boss.' The word 'Tesla' might refer to the famous scientist or the electric car company. Customers ordering a 'diet cola,' 'diet coke,' or a 'diet soda' might all expect to be served the same beverage. In MindMeld, the entity resolver identifies the unique and unambiguous concept associated with each entity.
Production conversational applications today rely on training data sets and supervised learning models to perform entity resolution. The training data utilized by MindMeld for this purpose resides in entity mapping files located in the entities folder of the application root directory.
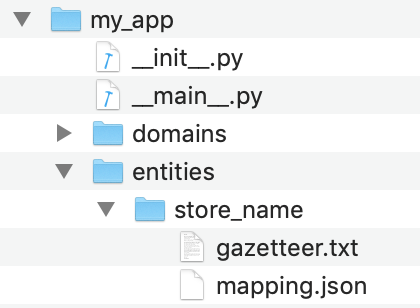
In this example, the mapping.json file under the store_name entity folder is the mapping file for the store_name entity. Here is what mapping.json looks like:
[
{
'id': '152323',
'cname': 'Pine and Market',
'whitelist': ['210 Pine Street', '210 Pine', 'Pine St']
},
{
'id': '102843',
'cname': 'Central Plaza',
'whitelist': ['Central', 'Main Street Plaza', '100 Main Street', '100 Main']
},
{
'id': '207492',
'cname': 'Market Square',
'whitelist': ['1 Market', '1 Market Square']
},
...
]
...
The entity mapping file specifies a canonical name, or cname, and a unique object id for the entity. Alternate names or synonyms by which users might refer to the entity are specified as items in the whitelist array. MindMeld relies on the data specified in this file in order to associate each natural language entity with a unique and unambiguous concept. See the User Guide for details.