Active Learning in MindMeld¶
Once a conversational application is deployed, capturing user logs can be highly beneficial to understand new trends and diversity of how users are phrasing their queries for different intents. These logs can improve the quality of the training data and overall classifier performance. However, manually analyzing these logs and annotating them with the correct domain, intent and entity labels is costly and time consuming. Moreover, as the number of users of the system increase, the number of logs to be annotated also increases by many folds. This reduces the scalability of the manual annotation process. In such scenarios, we can use active learning.
What is Active Learning?¶
In this section, we take a closer look at what active learning is and how it works within MindMeld.
Active Learning is an approach to continuously and iteratively pick data that is most informative for the models to train on from a pool of data-points. By choosing these informative data-points, active learning provides a higher chance of improving the accuracy of the model with fewer training examples. If the pool of data-points is unannotated, active learning also greatly reduces the number of queries that need manual annotation. MindMeld provides this inbuilt functionality to select these must-have queries from existing data or additional logs and datasets to get the best out of your conversational applications.
MindMeld's NLP pipeline consists of a hierarchy of classifier and tagger models for domain, intent, entity and role classification. Each classifier takes as input the query text and extracted features to generate a probability distribution for the corresponding classes in the hierarchy. These probability distributions can be strong indicators of the classifier's confidence in its prediction and can be useful in determining whether the query needs further reflection.
Say for a query A from the logs, the classifier assigns a probability of 0.95 or 95% to the selected class (i.e, the highest probability class) in the domain classifier and the remaining 5% is distributed amongst the rest of the domains. This indicates a high confidence by the classifier in its prediction. Whereas, for a query B, if the classifier assigns a probability 0.5 for the selected class, it would indicate a lower confidence in its prediction. Based on these confidence values, certain active learning strategies will select query B over query A which can be annotated and added to the training data. Once the classifier is trained with this additional data, it has a higher chance of performing better on similar confusable queries. Later sections explain how different strategies use these confidence scores to select important queries.
There are two phases in MindMeld's active learning pipeline. One, for configuring the best hyperparameters (such as the optimal strategy) for the pipeline and the other, for selecting the most important subset of queries from logs given the optimal configuration. These phases are referred to as Strategy Tuning and Query Selection respectively. Before diving deeper into these phases, let us take a look at the configuration file for setting up MindMeld's active learning pipeline.
Defining the AL config¶
Modifying the configuration file is the first step towards customizing the active learning pipeline to your application. This section details different components in the configuration along with the default values that are applied if no ACTIVE_LEARNING_CONFIG is defined in config.py. There are five main components:
- output_folder (str) - Directory path to save the output of the active learning pipeline.
- pre_tuning
| Configuration Key | Type | Definition and Examples |
|---|---|---|
| train_pattern | str | Regex pattern to match train files. Example for all train files ".*train.*.txt" |
| test_pattern | str | Regex pattern to match test files. Example for all test files ".*test.*.txt" |
| train_seed_pct | float | Percentage of training data to use as the initial seed |
- tuning
| Configuration Key | Type | Definition and Examples |
|---|---|---|
| n_classifiers | int | Number of classifier instances to be used by ensemble strategies |
| n_epochs | int | Number of turns strategy tuning is run on the complete train data |
| batch_size | int | Number of queries to sample at each iteration from the train data |
| tuning_level | list | Selecting the hierarchy level to use for tuning, options: ("domain" or "intent") and/or "entity" |
| classifier_tuning_strategies | List[str] | List of strategies (heuristics) to use for classifier (domain/intent) tuning options: "LeastConfidenceSampling", "EntropySampling", "MarginSampling", "RandomSampling", "KLDivergenceSampling", "DisagreementSampling", "EnsembleSampling" |
| tagger_tuning_strategies | List[str] | List of strategies (heuristics) to use for tagger (entity) tuning options: "LeastConfidenceSampling", "EntropySampling", "MarginSampling", |
- tuning_output
| Configuration Key | Type | Definition and Examples |
|---|---|---|
| save_sampled_queries | bool | Option to save the queries sampled at each iteration |
| aggregate_statistic | str | Aggregated classifier performance metric to record in the output and plots, options: "accuracy", "f1_weighted", "f1_macro", "f1_micro" |
| class_level_statistic | str | Class level performance metric to record in the output and plots, options: "f_beta", "percision", "recall" |
- query_selection
| Configuration Key | Type | Definition and Examples |
|---|---|---|
| classifier_selection_strategy | str | Classifier Strategy (heuristic) to use for log selection |
| tagger_selection_strategy | str | Tagger Strategy (heuristic) to use for log selection |
| log_usage_pct | float | Percentage of the log data to use for selection |
| labeled_logs_pattern | str | Regex pattern to match log files if already labeled correctly into the domain and intent hierarchy of the MindMeld app. For example, ".*log.*.txt" |
| unlabeled_logs_path | str | Path to text file containing unlabeled queries from user logs or other resources |
If there is no configuration defined in the config.py file or if fields are missing in the custom configuration, the relevant missing information is obtained from the following default configuration:
DEFAULT_ACTIVE_LEARNING_CONFIG = {
"output_folder": None,
"pre_tuning": {
"train_pattern": ".*train.*.txt",
"test_pattern": ".*test.*.txt",
"train_seed_pct": 0.20,
},
"tuning": {
"n_classifiers": 3,
"n_epochs": 5,
"batch_size": 100,
"tuning_level": ["domain"],
"classifier_tuning_strategies": [
"LeastConfidenceSampling",
"MarginSampling",
"EntropySampling",
"RandomSampling",
"DisagreementSampling",
"EnsembleSampling",
"KLDivergenceSampling",
],
"tagger_tuning_strategies": [
"LeastConfidenceSampling",
"MarginSampling",
"EntropySampling",
],
},
"tuning_output": {
"save_sampled_queries": True,
"aggregate_statistic": "accuracy",
"class_level_statistic": "f_beta",
},
"query_selection": {
"classifier_selection_strategy": "EntropySampling",
"tagger_selection_strategy": "EntropySampling",
"log_usage_pct": 1.00,
"labeled_logs_pattern": None,
"unlabeled_logs_path": "logs.txt",
},
}
Note
The default batch size is 100. For large applications, this number may be too small and we encourage developers to update it accordingly. We recommend setting 1-2% of total training data size as the batch size.
If the application consists of a single domain, choose 'intent' as the tuning level. If any domain consists of a single intent or any intent has no test files available, choose 'domain' as the tuning level.
If both 'domain' and 'intent' are chosen for tuning, system will automatically choose 'intent'.
Install the additional dependencies for active learning:
pip install mindmeld[active_learning]or in a zsh shell:
pip install mindmeld"[active_learning]"
Strategy Tuning¶
The goal of the strategy tuning phase in the active learning pipeline is to determine the best strategy (heuristic) and tuning level for your application. We will talk about the different possible strategies and tuning levels later in this section.
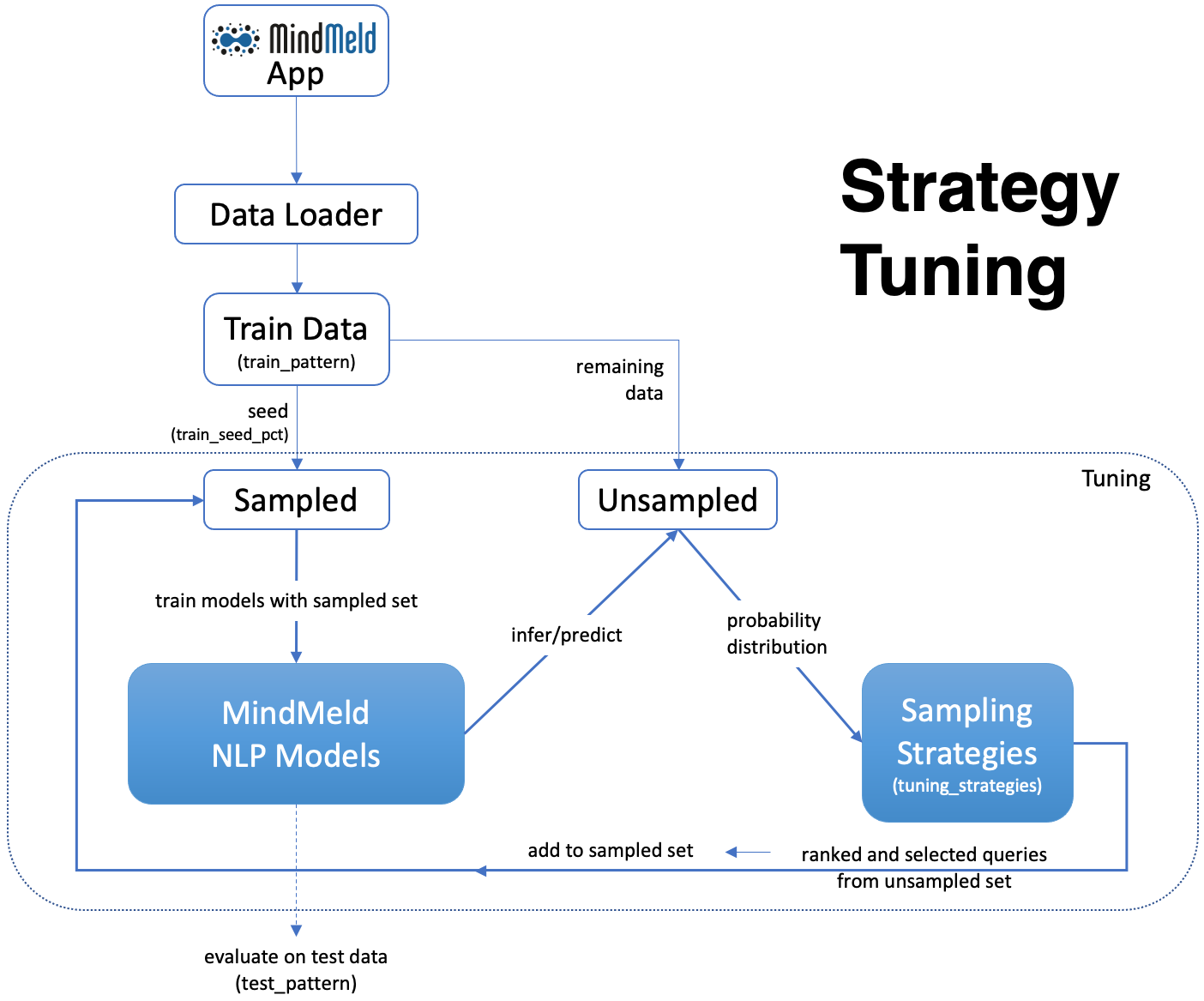
In this phase, the existing training data in the app is partitioned into a sampled seed set and unsampled set according to the train_seed_pct value mentioned in the config file. Data is evenly sampled based on given train_seed_pct across the different domains/intents to maintain class balance in the seed dataset. Note that the pipeline only uses the data from files that match the train_pattern regex in the config file in this step. The classifiers are trained on this sampled seed data (and evaluated on the existing test data, i.e. files matching test_pattern).
Next, the trained classifiers/taggers are used to generate a predictions for queries in the unsampled set. These predictions are output in the form of class probability distributions. The various tuning_strategies (both classifier_tuning_strategies and tagger_tuning_stategies) use these distributions to rank the queries. Based on this ranked list, the top-k queries (k = batch_size) are extracted from the unsampled set and added to the sampled set, thereby increasing the size of the latter while reducing that of the former.
The classifier/tagger models are now retrained with the expanded sampled set and evaluated against the same test set. This process is repeated until all the unsampled training data has been consumed by the sampled set and the final iteration of classifier/tagger training is done on this exhaustive sampled set. This tuning process is repeated for n_epochs (as defined in the config) to obtain average active learning performance.
Information about unsampled queries selected at each iteration, and the performance of classifiers/taggers for each tuning strategy is stored iteratively in the output_folder directory. For every tuning command run, a new experiment folder is generated in this directory with the performance results and corresponding plots for a better visual understanding of the results.
The following command can be used to run tuning using the settings defined in the application configuration:
mindmeld active_learning --tune --app-path '<PATH>/app_name/' --output_folder '<PATH>'
Flags for application path and output folder are required. In addition to the aforementioned required flags, the following optional flags can be used - tuning_level, batch_size, n_epochs, train_seed_pct, and plot (default True). These are described in detail in AL config section above. These flags overwrite the default configuration settings for active learning.
At the end of the tuning process, results are stored in the output_folder. The accuracy.json file in the directory output_folder/results consist of strategy performance on the application's test/evaluation data for every iteration and epoch. selected_queries.json consists of the same information but instead of evaluation performance, this file records the queries selected for that iteration. The output_folder/plots directory consists of the same quantitative information in a visual format. The plots record performance of all chosen strategies across iterations and give a sense of which strategy is best suited for your application. The same information can be gauged from these results and plots about the best tuning_level for your application.
Now, let us take a look at the different tuning strategies and levels. These hyperparameters are studied at the strategy tuning level with the best ones chosen for query selection based on the quantitative results and plots.
Strategies¶
The tuning step allows the application to run 7 possible strategies (classifier_tuning_strategies) for classifiers and 3 (tagger_tuning_strategies) for the tagger. This further allows for choosing the best performing ones. Each strategy is a sampling function that samples the worst performing queries from the unsampled set of training data. The assessment of worst performance comes from the classifiers'/taggers' confidence in the predictions for that query. All heuristics use this information differently as described next.
| Strategy | How does it work? | Tuning Type |
|---|---|---|
| Random Sampling | Samples the next set of queries at random. | Classifier only |
| Least Confidence Sampling | From the available queries in the batch, this sampling strategy samples queries with the lowest max confidence score across any class, i.e., queries that the classifier is least confident about the selected class. | Classifier & Tagger |
| Entropy Sampling | Calculates the entropy score of the classifier confidences per query. Samples the ones with highest entropy. | Classifier & Tagger |
| Margin Sampling | From the available queries in the batch, this sampling strategy samples queries that have the lowest confidence score difference between the top two class confidence scores for the query. This difference is referred to as the "margin". | Classifier & Tagger |
| Disagreement Sampling | Across n runs of the classifier, this sampling strategy calculates an agreement score for every query (% of classifiers that voted for the most frequent class). The queries are then ranked from lowest classifier agreement to highest and then sampled in order. | Classifier only |
| KL Divergence Sampling | Across n runs of the classifier, this sampling strategy calculates the KL divergence between average confidence distribution across all classifiers for a given class and the confidence distribution for a given query for that class. Queries with higher divergence are sampled. | Classifier only |
| Ensemble Sampling | Combines ranks from all the above heuristics and samples in order. | Classifier only |
Tuning Levels¶
Since MindMeld defines a NLP hierarchy of domains, intents and entities, the various heuristics can be computed by using the confidence scores or probabilities of either the domain or intent classifiers or those from the entity recognizer (tagger). This level is indicated by the tuning_level in the config.
- For the domain level, the domain classifier is run and the probability scores of the classifier are passed to the strategies.
- For the intent level, the intent classifier probability scores across all domains are concatenated into a single vector and passed on to the strategies.
- For the entity level, the entity recognizer (per tag) probability scores across all domains and intents are concatenated into a single vector and passed on to the strategies.
Once the tuning step has been completed and the results observed, a decision can be made on the best performing hyperparameters, strategy and tuning level for the query selection step.
Query Selection¶
Having obtained optimized hyperparameters through the tuning step, the pipeline is ready to run the query selection step. Here, the active learning pipeline picks the best subset of queries from the logs that can be added to the training files to give the maximum performance boost in terms of accuracy.
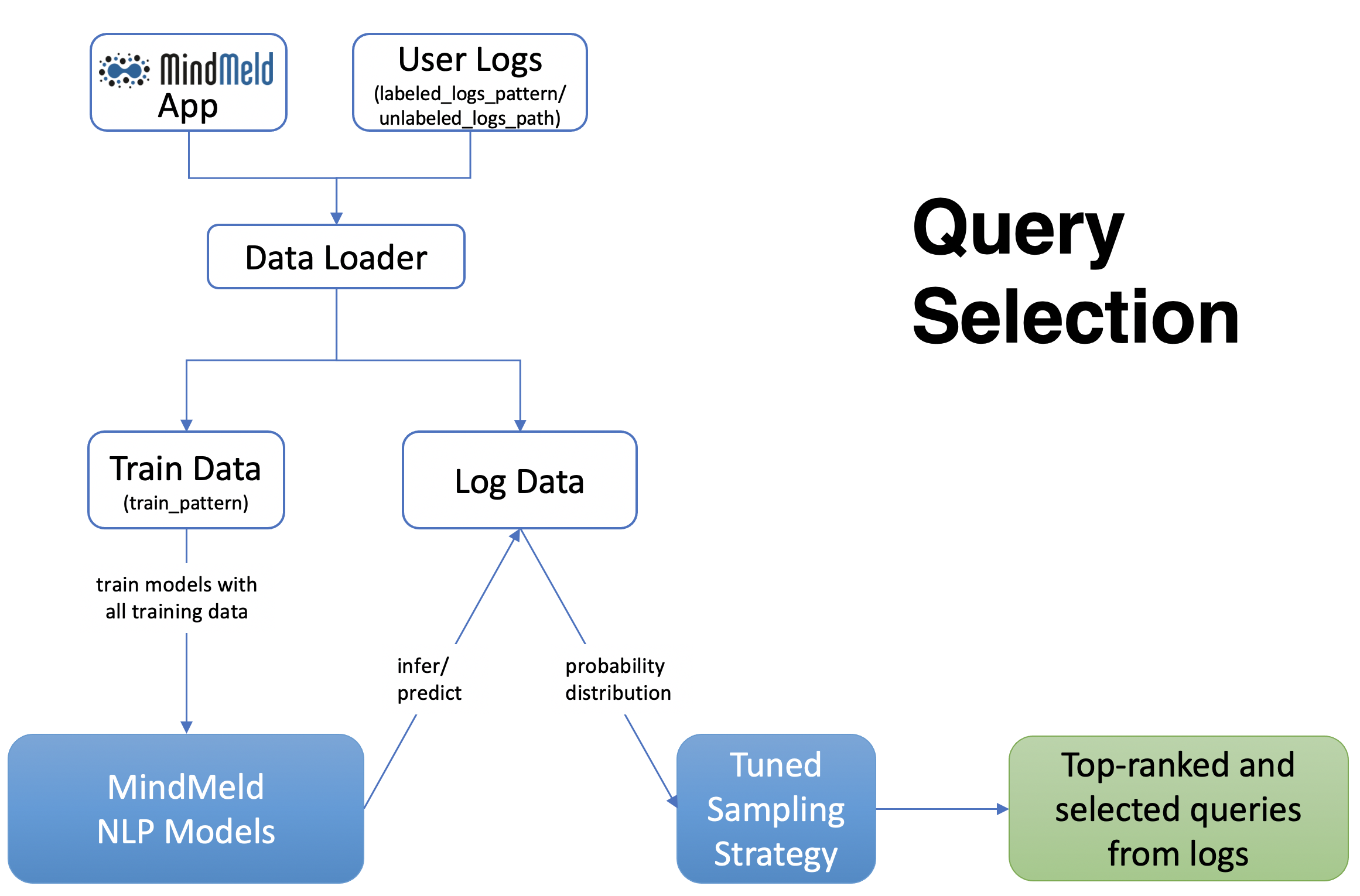
Two sets of data inputs are needed for the query selection step, application (train and test) data and user logs. The user logs can either be additionally annotated log files within the MindMeld application hierarchy (see labeled_logs_pattern in config) or an external text file consisting of log queries (unlabeled_logs_path). After processing the data through the active learning data loader, the train data and log data are obtained. Additionally, log_usage_pct is a configuration setting that can be used to determine what amount of the user logs should be considered for selection. By default all log data is considered available for selection.
At this point, the MindMeld classifiers/taggers are trained using the train data. These models are then used to infer predictions on the log data and generate classifier/tagger probability distributions for all queries. Note that only the classification/tagger level (domain/intent and/or entity) specified by the tuning_level is used in this step.
The probability distributions for log queries are then passed to the optimized sampling strategy decided at the tuning step. This sampling strategy then ranks and picks the most informative queries from the logs to complete the query selection process. The number of selected queries is determined through the batch_size flag or configuration parameter (default 100).
At this stage, the queries can be annotated and added to the train files of the MindMeld application. Next, we take a look at some options to run the query selection process.
The following command can be used to run query selection using the application's configuration, if the log file or the log files' pattern has been specified in the config:
mindmeld active_learning --select --app-path '<PATH>/app_name/' --output_folder '<PATH>'
Alternatively, path to unlabeled logs text file (unlabeled_logs_path) can be provided as a flag.
mindmeld active_learning --select --app-path "<PATH>/app_name/" --output_folder '<PATH>' --unlabeled_logs_path "<PATH>/logs.txt"
Also, if your log data is labeled and included in your MindMeld application you can specify the pattern for your log data using the following flag:
mindmeld active_learning --select --app-path '<PATH>/app_name/' --output_folder '<PATH>' --labeled_logs_pattern ".*log.*.txt"
Optional flags that can be used for selection include: batch_size, log_usage_pct, strategy.
Note
When selecting from labeled logs, ensure that the regex pattern provided in log pattern (labeled_logs_pattern) do not have an overlap with the regex patterns for train and test files in (train_pattern and test_pattern). In other words, ensure that the same files are not chosen by the system for train, test and log data.
Quick Reference¶
This section is a quick reference on the basic command-line usage of the active learning Strategy Tuning (tune) and Query Selection (select) commands. Refer the earlier sections for additional flags.
Strategy tuning
mindmeld active_learning --tune --app-path '<PATH>/app_name/' --output_folder '<PATH>'
Query selection
mindmeld active_learning --select --app-path "<PATH>/app_name/" --output_folder '<PATH>' --unlabeled_logs_path "<PATH>/logs.txt"
Note
- Running these commands without defining a custom active learning configuration in
config.pywould result in the use of a default configuration. The custom configuration settings and MindMeld's default active learning configuration are explained in the Defining the AL config section. - The results include two files for every tuning run, one to store the evaluation results across iterations and epochs against the test data and another file indicating the queries that were selected at each iteration. These evaluation and query selection results can be found in the directory
hr_assistant_active_learning/<experiment_folder>/resultsin filesaccuracies.jsonandselected_queries.jsonrespectively. Plots for the tuning results are saved inhr_assistant_active_learning/<experiment_folder>/plots. The experiment directory is unique to every tuning command run.