Using LSTM for Entity Recognition¶
Entity recognition is the one task within the NLP pipeline where deep learning models are among the available classification models. In particular, MindMeld provides a Bi-Directional Long Short-Term Memory (LSTM) Network, which has been shown to perform well on sequence labeling tasks such as entity recognition. The model is implemented in TensorFlow.
Note
Please make sure to install the Tensorflow requirement by running in the shell: pip install mindmeld[tensorflow].
LSTM network overview¶
The MindMeld Bi-Directional LSTM network
- encodes words as pre-trained word embeddings using Stanford's GloVe representation
- encodes characters using a convolutional network trained on the training data
- concatenates the word and character embeddings together and feeds them into the bi-directional LSTM
- couples the forget and input gates of the LSTM using a peephole connection, to improve overall accuracies on downstream NLP tasks
- feeds the output of the LSTM into a linear chain Conditional Random Field (CRF) or Softmax layer which labels the target word as a particular entity
The diagram below describes the architecture of a typical Bi-Directional LSTM network.
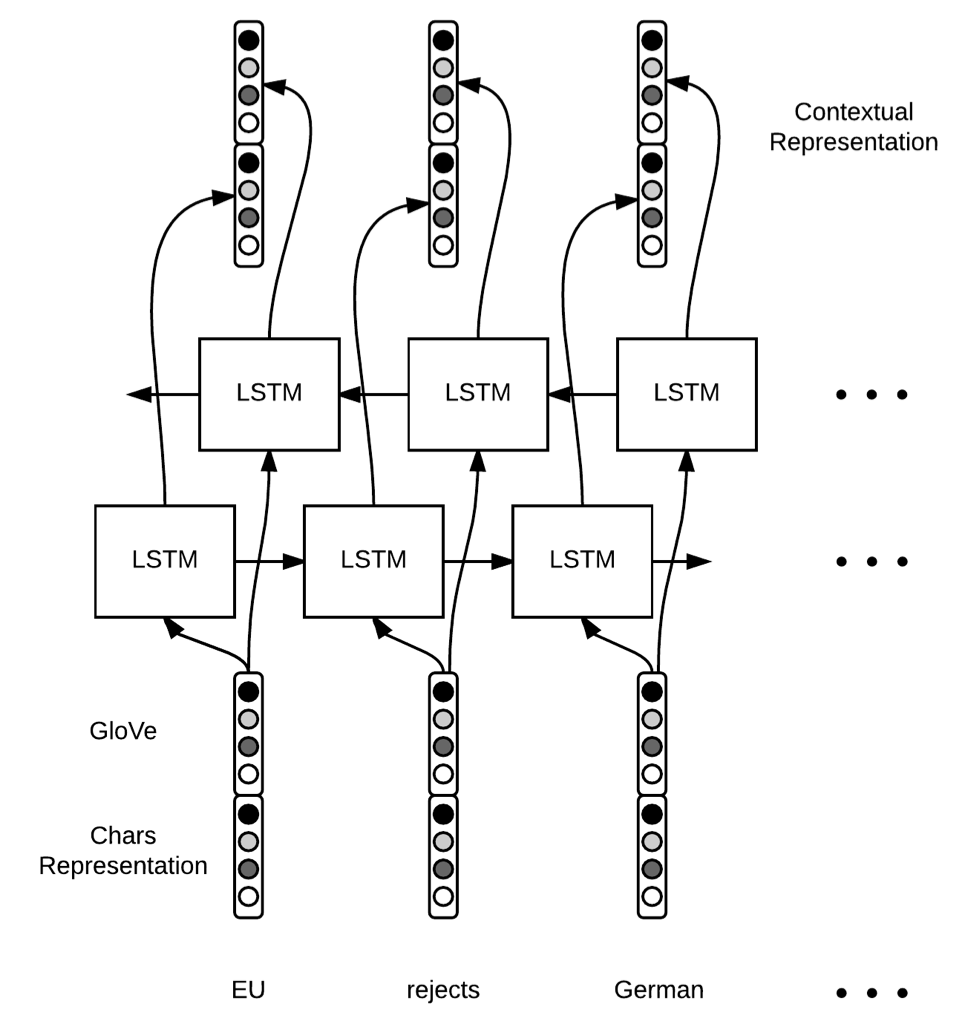
Courtesy: Guillaume Genthial
This design has these possible advantages:
- Deep neural networks (DNNs) outperform traditional machine learning models on training sets with about 1,000 or more queries, according to many research papers.
- DNNs require less feature engineering work than traditional machine learning models, because they use only two input features (word embeddings and gazetteers) compared to several hundred (n-grams, system entities, and so on).
- On GPU-enabled devices, the network can achieve training time comparable to some of the traditional models in MindMeld.
The possible disadvantages are:
- Performance may be no better than traditional machine learning models for training sets of about 1,000 queries or fewer.
- Training time on CPU-only machines is a lot slower than for traditional machine learning models.
- No automated hyperparameter tuning methods like sklearn.model_selection.GridSearchCV are available for LSTMs.
LSTM parameter settings¶
Parameter tuning for an LSTM is more complex than for traditional machine learning models. A good starting point for understanding this subject is Andrej Karpathy's course notes from the Convolutional Neural Networks for Visual Recognition course at Stanford University.
'params'(dict)A dictionary of values to be used for model hyperparameters during training.
| Parameter name | Description |
|---|---|
padding_length |
The sequence model treats this as the maximum number of words in a query.
If a query has more words than Typically set to the maximum word length of query expected both at train and predict time. Default: Example:
|
batch_size |
Size of each batch of training data to feed into the network (which uses mini-batch learning). Default: Example:
|
display_epoch |
The network displays training accuracy statistics at this interval, measured in epochs. Default: Example:
|
number_of_epochs |
Total number of complete iterations of the training data to feed into the network. In each iteration, the data is shuffled to break any prior sequence patterns. Default: Example:
|
optimizer |
Optimizer to use to minimize the network's stochastic objective function. Default: Example:
|
learning_rate |
Parameter to control the size of weight and bias changes of the training algorithm as it learns. This article explains Learning Rate in technical terms. Default: Example:
|
dense_keep_prob |
In the context of the ''dropout'' technique (a regularization method to prevent overfitting), keep probability specifies the proportion of nodes to "keep"—that is, to exempt from dropout during the network's learning phase. The Default: Example:
|
lstm_input_keep_prob |
Keep probability for the nodes that constitute the inputs to the LSTM cell. Default: Example:
|
lstm_output_keep_prob |
Keep probability for the nodes that constitute the outputs of the LSTM cell. Default: Example:
|
token_lstm_hidden_state_dimension |
Number of states per LSTM cell. Default: Example:
|
token_embedding_dimension |
Number of dimensions for word embeddings. Allowed values: [50, 100, 200, 300]. Default: Example:
|
gaz_encoding_dimension |
Number of nodes to connect to the gazetteer encodings in a fully-connected network. Default: Example:
|
max_char_per_word |
The sequence model treats this as the maximum number of characters in a word.
If a word has more characters than Usually set to the size of the longest word in the training and test sets. Default: Example:
|
use_crf_layer |
If set to If set to Default: Example:
|
use_character_embeddings |
If set to If set to Note: Using character embedding significantly increases training time compared to vanilla word embeddings only. Default: Example:
|
char_window_sizes |
List of window sizes for convolutions that the network should use to build the character embeddings. Usually in decreasing numerical order. Note: This parameter is needed only if Default: Example:
|
character_embedding_dimension |
Initial dimension of each character before it is fed into the convolutional network. Note: This parameter is needed only if Default: Example:
|
word_level_character_embedding_size |
The final dimension of each character after it is transformed by the convolutional network. Usually greater than Note: This parameter is needed only if Default: Example:
|